1. 说明
1.1. 许可证
Flowable在链接下发布:http://www.apache.org/licenses/LICENSE-2.0.html[Apache V2许可证]
1.2. 下载
下载url:http://www.flowable.org/downloads.html
1.3. 来源
(发行版包含了大部分作为JAR文件的源文件。Flowable的源代码可以在以下链接中找到url:https://github.com/flowable/flowable-engine)
1.4. 实验特性
标有*[EXPERIMENTAL]*的章节介绍不应认为是稳定的 所有具有.impl的类,在包名中是内部实现类,不能以任何方式被认为是稳定的或有保证的。但是,如果用户指南将任何类提到为配置值,则支持它们,并且可以认为它们是稳定的。
1.5. 安装必需的软件
运行Flowable需要JDK 8或以上版本。可以访问 Oracle Java SE downloads页面url:http://www.oracle.com/technetwork/java/javase/downloads/index.html。该页面上也有安装指导。安装完成后,可以执行 java -version 。能看到JDK的版本信息就说明安装成功了。
1.6. 报告问题
问题和评论可以在链接上讨论url:https://forum.flowable.org。问题可以在链接中创建url:https://github.com/flowable/flowengine/issue [我们的Github问题跟踪器]。
1.7. 内部实现类
在JAR文件中,包中的所有类都有.impl.在它们里面是实现类,应该被认为是内部的。对于实现类中的类或接口,没有提供稳定性保证。
2. 配置
2.1. 创建CmmnEngine
Flowable CMMN引擎通过名为+flowable.cmmn.cfg.xml+的XML文件进行配置。 请注意,如果您使用的是“springintegration,构建流程引擎的Spring样式”,则这不适用*。
获得CmmnEngine的最简单方法是使用org.flowable.cmmn.engine.CmmnEngineConfiguration类:
1CmmnEngine cmmnEngine = CmmnEngineConfiguration.createStandaloneCmmnEngineConfiguration();
这将在类路径上查找flowable.cmmn.cfg.xml文件,并根据该文件中的配置构造引擎。 以下代码段显示了示例配置。 以下部分将详细介绍配置属性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="cmmnEngineConfiguration" class="org.flowable.cmmn.engine.CmmnEngineConfiguration">
<property name="jdbcUrl" value="jdbc:h2:mem:flowable;DB_CLOSE_DELAY=1000" />
<property name="jdbcDriver" value="org.h2.Driver" />
<property name="jdbcUsername" value="sa" />
<property name="jdbcPassword" value="" />
<property name="databaseSchemaUpdate" value="true" />
</bean>
</beans>
请注意,配置XML实际上是一个Spring配置。 这并不意味着Flowable只能在Spring环境中使用!我们只是在内部利用Spring的解析和依赖注入功能来构建引擎。
也可以使用配置文件以编程方式创建CmmnEngineConfiguration对象。 也可以使用不同的bean id(例如,参见第3行)。
1
2
3
4
5
6
CmmnEngineConfiguration.
createCmmnEngineConfigurationFromResourceDefault();
createCmmnEngineConfigurationFromResource(String resource);
createCmmnEngineConfigurationFromResource(String resource, String beanName);
createCmmnEngineConfigurationFromInputStream(InputStream inputStream);
createCmmnEngineConfigurationFromInputStream(InputStream inputStream, String beanName);
也可以不使用配置文件,并基于创建配置默认值(有关更多信息,请参阅<< configurationClasses,不同支持的类>>)。
1
2
CmmnEngineConfiguration.createStandaloneCmmnEngineConfiguration();
CmmnEngineConfiguration.createStandaloneInMemCmmnEngineConfiguration();
所有这些CmmnEngineConfiguration.createXXX()方法返回CmmnEngineConfiguration,如果需要可以进一步调整。 调用buildCmmnEngine()操作后,创建一个 CmmnEngine:
1
2
3
4
CmmnEngine cmmnEngine = CmmnEngineConfiguration.createStandaloneInMemCmmnEngineConfiguration()
.setDatabaseSchemaUpdate(CmmnEngineConfiguration.DB_SCHEMA_UPDATE_TRUE)
.setJdbcUrl("jdbc:h2:mem:my-own-db;DB_CLOSE_DELAY=1000")
.buildCmmnEngine();
2.2. CmmnEngineConfiguration bean
flowable.cmmn.cfg.xml必须包含一个具有id值为’cmmnEngineConfiguration’的bean。
1 <bean id="cmmnEngineConfiguration" class="org.flowable.cmmn.engine.CmmnEngineConfiguration">
然后使用该bean构造CmmnEngine 。
-
org.flowable.cmmn.engine.impl.cfg.StandaloneInMemCmmnEngineConfiguration: this is a convenience class for unit testing purposes. Flowable will take care of all transactions. An H2 in-memory database is used by default. The database will be created and dropped when the engine boots and shuts down. When using this, no additional configuration is probably needed.
-
org.flowable.cmmn.spring.SpringCmmnEngineConfiguration: To be used when the CMMN engine is used in a Spring environment. See the Spring integration section for more information.
2.3. 数据源配置
有两种方法可以配置Flowable CMMN引擎将使用的数据库。 第一个选项是定义数据库的JDBC属性: * jdbcUrl: 数据库的JDBC URL. * jdbcDriver: 为特定数据库类型实现驱动程序. * jdbcUsername: 用于连接数据库的用户名. * jdbcPassword: 用于连接数据库的密码.
基于提供的JDBC属性构造的数据源将具有默认链接: http://www.mybatis.org/ [MyBatis]连接池设置。 可以选择设置以下属性来调整该连接池(取自MyBatis文档):
-
jdbcMaxActiveConnections: 连接池中处于被使用状态的连接的最大值。默认为10。
-
jdbcMaxIdleConnections: 连接池中处于空闲状态的连接的最大值。
-
jdbcMaxCheckoutTime: 连接被取出使用的最长时间,超过时间会被强制回收。 默认为20000(20秒)。
-
jdbcMaxWaitTime:这是一个底层配置,让连接池可以在长时间无法获得连接时, 打印一条日志,并重新尝试获取一个连接。(避免因为错误配置导致沉默的操作失败)。 默认为20000(20秒)。 示例数据库配置:
1
2
3
4
<property name="jdbcUrl" value="jdbc:h2:mem:flowable;DB_CLOSE_DELAY=1000" />
<property name="jdbcDriver" value="org.h2.Driver" />
<property name="jdbcUsername" value="sa" />
<property name="jdbcPassword" value="" />
我们的基准测试表明,在处理大量并发请求时,MyBatis连接池可能扛不住。 因此,我们建议使用javax.sql.DataSource实现并将其注入流程引擎配置(例如HikariCP,Tomcat JDBC连接池等):
1
2
3
4
5
6
7
8
9
10
11
12
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" >
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/flowable" />
<property name="username" value="flowable" />
<property name="password" value="flowable" />
<property name="defaultAutoCommit" value="false" />
</bean>
<bean id="cmmnEngineConfiguration" class="org.flowable.cmmn.engine.CmmnEngineConfiguration">
<property name="dataSource" ref="dataSource" />
...
请注意,Flowable 表单不附带允许您定义此类数据源的库。 所以你必须确保库在你的类路径上。
无论您使用的是JDBC还是数据源方法,都可以设置以下属性:
-
databaseType: 数据库类型,可以是如下的值(h2, mysql, oracle, postgres, mssql, db2).
-
databaseSchemaUpdate:允许您设置策略以在表单引擎启动和关闭时如何处理数据库表.
-
false(default): 在创建表单引擎时检查库模式的版本,如果版本不匹配则抛出异常. -
true: 在构建表单引擎时,执行检查并在必要时执行模式的更新。 如果schema不存在,则创建它. -
create-drop: 在创建表单引擎时创建schema,并在关闭流程引擎时删除schema.
-
2.4. JNDI方式数据源配置
默认情况下,Flowable Form的数据库配置包含在每个Web应用程序的WEB-INF/classes中的db.properties文件中。 这并不总是理想的,因为它 要求用户修改Flowable源中的db.properties并重新编译WAR文件,或者在每次部署时分解WAR并修改db.properties。 通过使用JNDI(Java命名和目录接口)获取数据库连接,连接完全由Servlet容器管理,并且可以在WAR部署之外管理配置。 这也允许对db.properties文件提供的连接参数进行更多控制。
2.4.1. 配置
JNDI数据源的配置将根据您使用的servlet容器应用程序而有所不同。 以下说明适用于Tomcat,但对于其他容器应用程序,请参阅容器应用程序的文档。
如果使用Tomcat,则在$CATALINA_BASE/conf/[enginename]/[hostname]/[warname].xml中配置JNDI资源(对于Flowable UI,这通常是$CATALINA_BASE/conf/Catalina/localhost/flowable-app。XML)。 首次部署应用程序时,将从Flowable WAR文件复制默认上下文,因此如果已存在,则需要替换它。 例如,要更改JNDI资源以便应用程序连接到MySQL而不是H2,请将文件更改为以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<?xml version="1.0" encoding="UTF-8"?>
<Context antiJARLocking="true" path="/flowable-app">
<Resource auth="Container"
name="jdbc/flowableDB"
type="javax.sql.DataSource"
description="JDBC DataSource"
url="jdbc:mysql://localhost:3306/flowable"
driverClassName="com.mysql.jdbc.Driver"
username="sa"
password=""
defaultAutoCommit="false"
initialSize="5"
maxWait="5000"
maxActive="120"
maxIdle="5"/>
</Context>
2.4.2. JNDI 属性
要配置JNDI数据源,请在Flowable UI的属性文件中使用以下属性:
-
spring.datasource.jndi-name=: 数据源的JNDI名称.
-
datasource.jndi.resourceRef: 设置查询是否发生在J2EE容器中,换句话说,如果JNDI名称尚未包含它,则需要添加前缀“java:comp/env/”。 默认为“true”.
2.5. 支持的数据库厂商
下面列出了Flowable用于引用数据库的类型(区分大小写!)。ses.
| 数据库类型 | 连接URL | Notes |
|---|---|---|
h2 |
jdbc:h2:tcp://localhost/flowable_form |
Default configured database |
mysql |
jdbc:mysql://localhost:3306/flowable_form?autoReconnect=true |
Tested using mysql-connector-java database driver |
oracle |
jdbc:oracle:thin:@localhost:1521:xe |
|
postgres |
jdbc:postgresql://localhost:5432/flowable_form |
|
db2 |
jdbc:db2://localhost:50000/flowable_form |
|
mssql |
jdbc:sqlserver://localhost:1433;databaseName=flowable_form (jdbc.driver=com.microsoft.sqlserver.jdbc.SQLServerDriver) OR jdbc:jtds:sqlserver://localhost:1433/flowable_form (jdbc.driver=net.sourceforge.jtds.jdbc.Driver) |
Tested using Microsoft JDBC Driver 4.0 (sqljdbc4.jar) and JTDS Driver |
2.6. 创建表
为数据库创建数据库表的最简单方法是:
-
在classpath中添加flowable-cmmn-engine JARS包
-
添加合适的数据库驱动
-
将Flowable配置文件(flowable.cmmn.cfg.xml)添加到类路径中,指向您的数据库(请参阅<< databaseConfiguration,数据库配置部分>>)
-
执行DbSchemaCreate类的main方法
但是,通常只有数据库管理员才能在数据库上执行DDL语句。 在生产系统中,这也是最明智的选择。 可以在Flowable下载页面或Flowable分发文件夹内的database 子目录中找到SQL DDL语句。 这些脚本也在引擎JAR(flowable-cmmn-engine-x.jar)中,在包org/ flowable/cmmn/db /create中。 SQL文件的形式
flowable.{db}.cmmn.create.sql
其中db是<< supporteddatabases,supported databases >>中的任何一个。
2.7. 数据库表名称解释
Flowable CMMN Engine的数据库名称均以* ACT_CMMN_ *开头。
-
ACT_CMMN_*: 没有附加前缀的表包含“static”信息,例如案例定义和案例资源(图像,规则等)。
-
ACT_CMMN_RU_*: 'RU’代表+运行时+。 这些是包含案例实例,计划项目等的运行时数据的运行时表。 Flowable仅在案例实例执行期间存储运行时数据,并在案例实例结束时删除记录。 这使运行时表保持小而快。
-
ACT_CMMN_HI_*:'HI’代表历史。 这些是包含历史数据的表,例如过去的案例实例,计划项等。
2.8. 数据库升级
在运行升级之前,请确保备份数据库(使用数据库备份功能)。
默认情况下,每次创建流程引擎时都会执行版本检查。 这通常在应用程序或Flowable Web应用程序的引导时发生一次。 如果Flowable库注意到库版本与Flowable数据库表的版本之间的差异,则抛出异常。
要升级,必须首先将以下配置属性放在flowable.cmmn.cfg.xml配置文件中:
1
2
3
4
5
6
7
8
9
10
<beans >
<bean id="cmmnEngineConfiguration"
class="org.flowable.cmmn.engine.CmmnEngineConfiguration">
<!-- ... -->
<property name="databaseSchemaUpdate" value="true" />
<!-- ... -->
</bean>
</beans>
使用databaseSchemaUpdate设置为true即可完成自动升级。
2.9. 历史配置
自定义历史存储的配置是可选的。 这允许您调整影响引擎的“历史记录,历史记录功能”的设置。 有关详细信息,请参阅<< historyConfig,history configuration >>。
1<property name="history" value="audit" />
2.10. 在表达式和脚本中公开配置bean
默认情况下,您在flowable.cmmn.cfg.xml配置或您自己的Spring配置文件中指定的所有bean都可用于表达式和脚本。 如果要限制配置文件中bean的可见性,可以在流程引擎配置中配置名为beans的属性。 CmmnEngineConfiguration中的beans属性是一个map。 指定该属性时,表达式和脚本只能看到该映射中指定的bean。 暴露的bean将使用您在地图中指定的名称公开。
2.11. 部署缓存配置
所有定义都被缓存(在解析之后),以避免每次需要表单时都访问数据库,并且表单数据不会更改。 默认情况下,此缓存没有限制。 要限制表单缓存使用的容器大小,请添加以下属性:
1<property name="caseDefinitionCacheLimit" value="10" />
设置此属性将使默认的LRU算法。 当然,此属性的“最佳”值取决于存储的案例总量和运行时实际使用的案例数。
您也可以注入自己的缓存实现。 这必须是实现org.flowable.engine.common.impl.persistence.deploy.DeploymentCache接口的bean:
1
2
3
<property name="caseDefinitionCache">
<bean class="org.flowable.MyCache" />
</property>
2.12. 日志
所有日志记录(flowable,spring,mybatis,…)都通过SLF4J进行路由,并允许选择您选择的日志记录实现。
*默认情况下,flowable-dmn-engine依赖项中不存在SFL4J-binding jar,这应该在项目中添加,以便使用您选择的日志框架。 *如果没有添加实现jar,SLF4J将使用NOP-logger,不记录任何内容,除了警告不会记录任何内容。 有关这些绑定链接的更多信息,请访问:http://www.slf4j.org/codes.html#StaticLoggerBinder[http://www.slf4j.org/codes.html#StaticLoggerBinder]。 使用Maven,添加例如这样的依赖(这里使用log4j),请注意您仍然需要添加一个版本:
1
2
3
4
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</dependency>
flowable-ui和flowable-rest webapps配置了使用Log4j binding.。 在运行所有flowable-*模块的测试时也使用Log4j。
在类路径中使用带有commons-logging的容器时的重要注意事项: 为了通过SLF4J路由spring-logging,使用了一个桥接器(参见链接:http://www.slf4j.org/legacy.html#jclOverSLF4J[http://www.slf4j.org/legacy.html#jclOverSLF4J])。 如果您的容器提供了commons-logging实现,请按照此页面上的说明进行操作:http://www.slf4j.org/codes.html#release[http://www.slf4j.org/codes.html#release]确保稳定性。
使用Maven时的示例(省略版本):
1
2
3
4
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
</dependency>
3. The Flowable CMMN API
3.1. 流程 CMMN 引擎 API 与服务类
引擎 API 是与 Flowable 交互的最常用方式。核心起点是可以通过配置部分中描述的几种方式创建的 CMMN 引擎。从 CMMN 引擎中,您可以获得包含案例/CMMN 方法的各种服务类。CMMN 引擎和其服务类对象是线程安全的,因此您可以为整个服务保留其中一个引用。
1
2
3
4
5
6
7
CmmnEngine cmmnEngine = CmmnEngineConfiguration.createStandaloneCmmnEngineConfiguration();
CmmnRuntimeService runtimeService = cmmnEngine.getCmmnRuntimeService();
CmmnRepositoryService repositoryService = cmmnEngine.getCmmnRepositoryService();
CmmnTaskService taskService = cmmnEngine.getCmmnTaskService();
CmmnManagementService managementService = cmmnEngine.getCmmnManagementService();
CmmnHistoryService historyService = cmmnEngine.getCmmnHistoryService();
CmmnEngineConfiguration.createStandaloneCmmnEngineConfiguration() 将初始化并构建 CMMN 引擎,然后始终返回这个 CMMN 引擎。
CmmnEngineConfiguration 类将扫描所有 flowable.cmmn.cfg.xml 和 flowable-cmmn-context.xml 配置文件。对于所有 flowable.cmmn.cfg.xml 配置文件,CMMN 引擎将以典型的 Flowable 方式构建:CmmnEngineConfiguration.createCmmnEngineConfigurationFromInputStream(inputStream).buildCmmnEngine()。对于所有 flowable-cmmn-context.xml 配置文件,CMMN 引擎将以 Spring 方式构建:首先创建 Spring 应用程序上下文,然后 CMMN 引擎会从该应用程序上下文中获取。
所有的服务类均是无状态的。这意味着您可以轻松地在群集中的多个节点上运行Flowable,每个节点都连接同一个数据库,而不必担心哪台机器实际执行了旧的调用。对任何服务类的任何调用都是幂等的,无论它在何处执行。
CmmnRepositoryService 可能是 Flowable CMMN 引擎工作时所需的第一个服务类。该服务类提供用于管理和使用部署文件和案例定义的操作。案例定义是 CMMN 1.1案例的 Java 对应物,它表示案例的每个步骤的结构和行为,这里不再过多介绍。部署文件是 Flowable CMMN 引擎中的打包单元。部署文件可以包含多个CMMN 1.1 XML文件和任何其他资源,其中具体包含哪些内容取决于开发人员。它的范围可以从单个流程 CMMN 1.1 XML 文件到整个案例和相关资源的包(例如,部署文件“hr-cases”可能包含与 HR 案例相关的所有内容)。CmmnRepositoryService 可以发布这样的包。发布一个部署文件意味着将其上载到引擎,在该引擎中,所有案例在存储到数据库之前都会被检查和解析。从那一刻起,系统会感知到这个部署文件,并且部署文件中包含的任何流程都可以被发起。
此外,这个服务类允许您:
-
查询引擎已知的部署文件和案例定义。
-
检索各种资源,例如部署文件中包含的文件或引擎自动生成的案例图。
-
检索案例定义的 POJO 版本,它可用于使用 Java 而不是 JSON 进行内省。
CmmnRepositoryService 主要与静态信息(数据不会改变,至少不会变很多)有关,而 CmmnRuntimeService 恰恰相反,它涉及启动案例定义的新案例实例。如上所述,案例定义定义了案例的不同步骤的结构和行为。案例实例是案例定义的一次执行。对于每个案例定义,通常会有许多实例同时运行。CmmnRuntimeService 也是用于检索和存储案例变量的服务类。变量是特定于指定案例实例的数据,并且可以让案例中的各种结构使用(例如,方案的跳转条件通常使用流程变量来确定选择哪个路径来继续流转该案例)。CmmnRuntimeService 还允许您查询案例实例和方案条目。方案条目是 CMMN 1.1的已启用方案条目的表示。最后,无论何时案例实例需要继续流转并等待外部触发时都会使用 CmmnRuntimeService。案例实例可以具有各种等待状态,该服务类包含各种操作来向实例“发信号”并由外部触发器接收,然后案例实例可以继续流转。
需要由系统的操作用户执行的任务是 Flowable 这类 CMMN 引擎的核心。围绕任务的所有内容都分组在 CmmnTaskService 中,例如:
-
查询分配给用户或组的任务
-
创建新的独立任务,这些任务与流程实例无关。
-
操作派遣任务的参与人或以某种方式参与任务的用户。
-
签收并完成一个任务。 签收意味着某人决定成为该任务的操作人,这意味着该用户将审批该任务,审批意味着“完成任务”。通常这是填写一种表单。
CmmnHistoryService 暴露 Flowable CMMN 引擎收集的所有历史数据。在执行案例时,引擎可以保存大量数据(可以通过配置决定是否启用),例如案例实例开始时间,谁执行哪些任务,审批任务花费多长时间,每个案例实例流经哪条路径等。此服务类主要暴露查询功能以访问此类数据。
CmmnManagementService 提供对数据库表低级信息的访问,允许查询不同类型的工作并执行它们。
有关服务操作和引擎 API 的更多详细信息,请参阅文档。
3.2. 异常策略
Flowable 中的基础异常是 org.flowable.engine.FlowableException,这是一个未经检查的异常。这种异常可以被 API 随时抛出,其他特定方法中发生的“预期中的”异常被记录在文档中。例如 CmmnTaskService 的摘录:
1
2
3
4
5
6
/**
* 成功执行任务时调用。
* @param taskId 要完成的任务的id,不能为空。
* @throws FlowableObjectNotFoundException 当指定id的任务不存在时抛出。
*/
void complete(String taskId);
在上面的示例中,当传递不存在的任务 id 时,将抛出异常。同样的,由于 Java 文档明确声明 taskId 不能为 null,因此在传递 null 时将抛出 FlowableIllegalArgumentException 。
尽管我们想要避免一个大的异常层次结构,下列的异常子类仍会在特定情况下被抛出。在流程执行或 API 调用期间发生的所有其他错误都不适合下面可能发生的异常,这些错误将作为常规 FlowableExceptions 抛出。
-
FlowableWrongDbException:当 Flowable 引擎发现数据库 Schema 版本与引擎版本不匹配时抛出。 -
FlowableOptimisticLockingException:当由同一数据条目的并发访问引起的数据存储中发生乐观锁问题时抛出。 -
FlowableClassLoadingException:当未找到请求加载的类或加载时发生错误时抛出(例如 Java 代理类、任务监听器等)。 -
FlowableObjectNotFoundException:当请求或操作的对象不存在时抛出。 -
FlowableIllegalArgumentException:这个异常表示在 Flowable API 调用中使用了非法参数、在引擎的配置中配置了非法值。 -
FlowableTaskAlreadyClaimedException:当一个任务已经被签收时,再次调用taskService.claim(…)时抛出。
3.3. 查询 API
有两种方法可以从引擎查询数据:使用查询 API 和本地查询。查询 API 允许您使用流畅的 API 编写完全类型安全的查询。您可以为查询添加各种查询条件(所有条件共同应用逻辑与)与一个排序参数。示例如下:
1
2
3
4
List<Task> tasks = taskService.createTaskQuery()
.taskAssignee("kermit")
.orderByDueDate().asc()
.list();
3.4. 变量
每个案例实例都需要并使用数据来执行自身节点来进行流转。在 Flowable 中, 这种数据被称为变量, 它们存储在数据库中。变量可以在表达式中使用(例如在哨兵的条件中)、在调用外部服务时的 Java 服务任务中使用(例如提供输入或存储服务调用的结果)等。
案例实例可以包含变量(称为案例变量), 同样的方案条目实例和人工任务也可以包含变量。案例实例可以包含任意数量的变量。每个变量都存储在 ACT_RU_VARIABLE 数据库表的一行中。
createCaseInstanceBuilder_方法具有可选方法,用于通过 _CmmnRuntimeService 创建案例实例并启动时提供变量:
1CaseInstance caseInstance = runtimeService.createCaseInstanceBuilder().variable("var1", "test").start();
在案例执行期间可以添加变量。例如 CmmnRuntimeService:
1void setVariables(String caseInstanceId, Map<String, ? extends Object> variables);
如下所示,变量同样可以被检索。请注意 CmmnTaskService 上存在类似的方法。
1
2
Map<String, Object> getVariables(String caseInstanceId);
Object getVariable(String caseInstanceId, String variableName);
变量通常用于 Java 服务任务、达式和脚本中等。
3.5. 临时变量
临时变量是行为类似于常规变量的变量,但不是持久变量。通常,临时变量用于高级用例。如有疑问,请使用常规案例变量。
以下情况适用于临时变量:
-
临时变量根本不会存储历史记录。
-
与常规变量一样,临时变量在设置时会放在最高级父节点上。这意味着在方案条目上设置变量时,临时变量实际存储在案例执行实例中。与常规变量一样,如果在特定方案条目或任务上设置变量,则存在方法的本地变体。
-
临时变量只能在案例定义中的下一个“等待状态”之前访问。在那之后无法访问。在这里,等待状态表示案例实例中持久化到数据存储的时间点。
-
临时变量只能由 setTransientVariable(name, value) 设置,但在调用 getVariable(name) 时也会返回临时变量(临时变量在 getTransientVariable(name) 中也存在,它只检查瞬态变量)。这样做的原因是使表达式的编写变得容易,并且使用变量的现有逻辑适用于这两种变量类型。
-
临时变量会优先于相同名称的持久变量。这意味着当在同一案例实例上设置相同名称的持久变量和临时变量后调用 getVariable("someVariable") 时,将返回临时变量值。
您可以在暴露常规变量的大多数地方设置和获取临时变量:
-
在 PlanItemJavaDelegate 实现中的 DelegatePlanItemInstance 上
-
通过运行时服务类启动案例实例时
-
审批一个任务时
这些方法遵循常规案例变量的命名约定:
1CaseInstance caseInstance = runtimeService.createCaseInstanceBuilder().transientVariable("var1", "test").start();
3.6. 表达式
Flowable 使用 UEL 进行表达式解析。UEL 即 Unified Expression Language(统一表达语言)并且是 Java EE 6规范的一部分(详情参见 Java EE6 规范 )。
表达式可用于例如 Java 服务任务和方案条目流转。虽然有两种类型的表达式:值表达式和方法表达式,但 Flowable 对此进行了抽象,因此它们都可以在需要表达式的地方使用。
-
值表达式:解析为一个值。默认情况下,可以使用所有案例变量。此外,所有 Spring-beans(如果使用 Spring 的话)都可用于表达式。一些例子:
${myVar}
${myBean.myProperty}
-
方法表达式:调用带或不带参数的方法。在调用不带参数的方法时,请确保在方法名称后添加空括号(因为这会将方法表达式与值表达式区分开来)。传递的参数可以是文本值或自己解析的表达式。例子:
${printer.print()}
${myBean.addNewOrder('orderName')}
${myBean.doSomething(myVar, planItemInstance)}
请注意,这些表达式支持解析基础数据类型(包括比较它们)、Bean、列表、数组和集合。
除了所有流程变量之外,还有一些可用于表达式的默认对象:
-
caseInstance:DelegateCaseInstance拥有有关正在进行的案例实例的额外信息。 -
planItemInstance:DelegatePlanItemInstance拥有有关当前方案条目的额外信息。
3.7. 函数表达式
[实验]表达式函数已在6.4.0版中添加。
为了更容易处理案例变量,在 variables 命名空间下可以使用一组开箱即用的函数。
-
variables:get(varName):检索变量的值。与直接在表达式中写入变量名称的主要区别在于,当变量不存在时,使用此函数不会抛出异常。例如,如果 myVariable 不存在,${myVariable == "hello"} 将会抛出异常,而 ${var:get(myVariable) == hello} 将正常工作。
-
variables:getOrDefault(varName, defaultValue):与 get(varName) 类似,但可以选择提供默认值,该值在未设置变量或值为 null 时返回。
-
variables:exists(varName):如果变量具有非 null 值,则返回 true 。
-
variables:isEmpty(varName) (别名 :empty):检查变量值是否为空。 根据变量类型,行为如下:
-
对于 String 变量,如果变量是空字符串,则该变量被视为空。
-
对于
java.util.Collection变量,如果集合没有元素,则返回 true。 -
对于
ArrayNode变量,如果没有元素,则返回 true -
如果变量是 null,则始终返回 true
-
-
variables:isNotEmpty(varName) (别名 :notEmpty):isEmpty(varName) 的取反操作。
-
variables:equals(varName, value)(别名_ :eq):检查变量是否等于给定值。这是表达式的简写函数,否则将写为 ${execution.getVariable("varName") != null && execution.getVariable("varName") == value}。
-
如果变量值为 null,则返回 false(除非与 null 比较)。
-
-
variables:notEquals(varName, value)(别名 :ne):equals(varName, value) 的取反操作。
-
variables:contains(varName, value1, value2, …): 检查提供的所有值是否包含在变量中。根据变量类型,行为如下:
-
对于 String 变量,传递的值需要全部为变量一部分子字符串
-
对于
java.util.Collection变量,所有传递的值都需要是集合的元素(常规 contains 语义)。 -
对于
ArrayNode变量,支持检查 ArrayNode 是否包含作为变量类型支持的类型的 JsonNode -
当变量值为 null 时,在所有情况下都返回 false。如果变量值不为 null,并且实例类型不是上述类型之一,则将返回 false。
-
-
variables:containsAny(varName, value1, value2, …) :类似于 contains 函数,但如果存在(不需要全部存在)传递的值包含在变量中,则返回 true。
-
比较函数:
-
variables:lowerThan(varName, value)(别名 :lessThan 或 :lt):${execution.getVariable("varName") != null && execution.getVariable("varName") < value} 的简写函数。
-
variables:lowerThanOrEquals(varName, value)(别名 :lessThanOrEquals 或 :lte):与上面的类似,相当于 < =
-
variables:greaterThan(varName, value) (别名 :gt):与上面的类似,相当于 >
-
variables:greaterThanOrEquals(varName, value) (别名 :gte):与上面的类似,相当于 > =
-
variables 命名空间的别名为 vars 或 var。因此 variables:get(varName) 等同于使用 vars:get(varName) 或 var:get(varName)。请注意,不需要再次在变量名称周围加上引号:var:get(varName) 等同于 var:get('varName') 或 var:get("varName")。
另请注意,在上述任何函数中,都不需要将 planItemInstance 或 caseInstance 传递给函数(它们在不使用函数时需要传递)。在调用函数时,引擎将注入适当的变量作用域。这也意味着在 BPMN 流程定义中编写表达式时,可以以完全相同的方式使用这些函数。
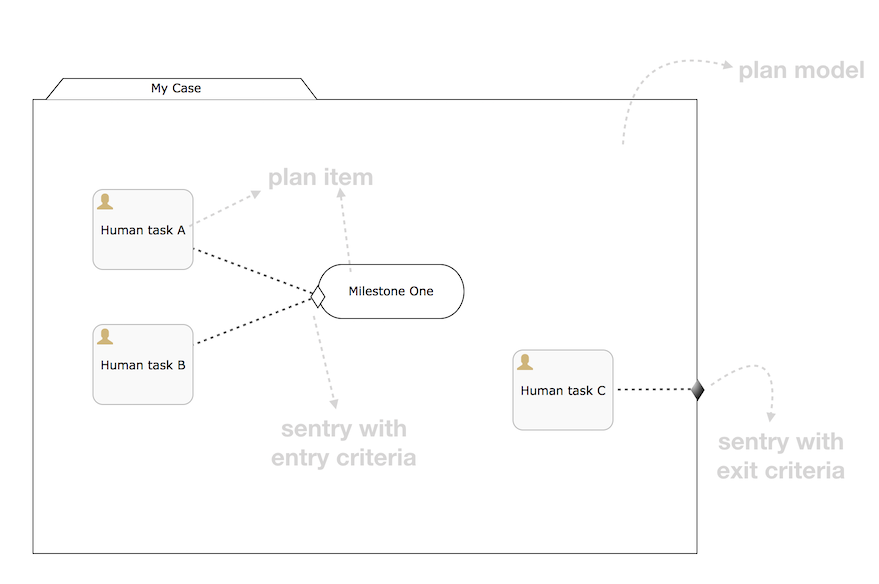
这些变量函数的使用在 CMMN 中尤其有用,例如在写入 if 部分的哨兵条件时,采用以下 CMMN 案例定义:
Assume the sentry has an if-part besides the completion event. Right after a case instance is started, this if-part condition will be evaluated (as the stage becomes available). If the condition is of the form ${someVariable == someValue}, this means the variable needs to be available when starting the case instance. In many cases, this is not possible or the variable comes later (e.g. from a form), which leads to a low-level PropertyNotFoundException. Taking the potential nullability in account, the correct expression would have to be: 假设哨兵除了完成事件之外还有一个 if 部分。在启动案例实例后,将评估此 if 部分条件(当此阶段变为可用时)。如果条件的形式为 ${someVariable == someValue},则表示该变量在启动案例实例时就将可用。在许多情况下,这是不可能的,或者变量稍后才会出现 (例如来自一个表单),这会导致一个低级的 PropertyNotFoundException。考虑到潜在的可空性,正确的表达必须是:
${planItemInstance.getVariable('someVariable') != null && planItemInstance.getVariable('someVariable') == someValue}
这很长。但是,使用上述功能可以简化为
${var:eq(someVariable, someValue)}
或者
${var:get(someVariable) == someValue}
函数实现考虑了变量的可空性(并且在变量为 null 的情况下不抛出异常)并且将正确地处理相等性。
此外,可以注册自定义函数在表达式中使用。有关更多信息,请参阅 org.flowable.common.engine.api.delegate.FlowableFunctionDelegate 接口。
3.8. 单元测试
案例是软件项目不可或缺的一部分,它们应该以与测试正常应用程序逻辑相同的方式进行测试:使用单元测试。 由于 Flowable 是一个嵌入式的 Java 引擎,因此为业务案例编写单元测试就像编写常规单元测试一样简单。
Flowable 支持 JUnit 4、JUnit 5 做单元测试。
在 JUnit 5中,需要使用 org.flowable.cmmn.engine.test.FlowableCmmnTest 注解或手动注册 org.flowable.cmmn.engine.test.FlowableCmmnExtension。
FlowableCmmnTest 注释是一个元注释,实现了对 FlowableCmmnExtension 的注册(即它实现了 @ExtendWith(FlowableCmmnExtension.class))。
这将使 CmmnEngine 和其服务类可用作测试和生命周期方法的参数(@BeforeAll、@BeforeEach、@AfterEach、@AfterAll)。
在每次测试之前,默认会使用类路径上的 flowable.cmmn.cfg.xml 配置文件初始化 CmmnEngine。
为了指定不同的配置文件,需要使用 org.flowable.cmmn.engine.test.CmmnConfigurationResource 注解(参见第二个示例)。
使用相同的配置文件时,CMMN 引擎会在多个单元测试之间静态缓存。
通过使用 FlowableCmmnExtension,您可以对测试方法使用 org.flowable.cmmn.engine.test.CmmnDeployment 注解。
当使用有 @CmmnDeployment 注解的测试方法时,在每次测试之前,将会发布在 CmmnDeployment#resources 下定义的 cmmn 文件。
如果没有定义资源,将发布与测试类在同一包中的 testClassName.testMethod.cmmn 形式的资源文件。
在测试结束时,部署文件将会删除,包括所有相关的案例实例、定义等。
有关更多信息,请参阅 CmmnDeployment 类。
考虑到所有这些,JUnit 5单元测试看起来如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@FlowableCmmnTest
class MyTest {
private CmmnEngine cmmnEngine;
private CmmnRuntimeService cmmnRuntimeService;
private CmmnTaskService cmmnTaskService;
@BeforeEach
void setUp(CmmnEngine cmmnEngine) {
this.cmmnEngine = cmmnEngine;
this.cmmnRuntimeService = cmmnEngine.getCmmnRuntimeService();
this.cmmnTaskService = cmmnEngine.getTaskRuntimeService();
}
@Test
@CmmnDeployment
void testSingleHumanTask() {
CaseInstance caseInstance = cmmnRuntimeService.createCaseInstanceBuilder()
.caseDefinitionKey("myCase")
.start();
assertNotNull(caseInstance);
Task task = cmmnTaskService.createTaskQuery().caseInstanceId(caseInstance.getId()).singleResult();
assertEquals("Task 1", task.getName());
assertEquals("JohnDoe", task.getAssignee());
cmmnTaskService.complete(task.getId());
assertEquals(0, cmmnRuntimeService.createCaseInstanceQuery().count());
}
}
使用 JUnit 5,您还可以将部署文件的 ID(使用 org.flowable.cmmn.engine.test.CmmnDeploymentId)注入到测试和生命周期方法中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@FlowableCmmnTest
@CmmnConfigurationResource("flowable.custom.cmmn.cfg.xml")
class MyTest {
private CmmnEngine cmmnEngine;
private CmmnRuntimeService cmmnRuntimeService;
private CmmnTaskService cmmnTaskService;
@BeforeEach
void setUp(CmmnEngine cmmnEngine) {
this.cmmnEngine = cmmnEngine;
this.cmmnRuntimeService = cmmnEngine.getCmmnRuntimeService();
this.cmmnTaskService = cmmnEngine.getTaskRuntimeService();
}
@Test
@CmmnDeployment
void testSingleHumanTask() {
CaseInstance caseInstance = cmmnRuntimeService.createCaseInstanceBuilder()
.caseDefinitionKey("myCase")
.start();
assertNotNull(caseInstance);
Task task = cmmnTaskService.createTaskQuery().caseInstanceId(caseInstance.getId()).singleResult();
assertEquals("Task 1", task.getName());
assertEquals("JohnDoe", task.getAssignee());
cmmnTaskService.complete(task.getId());
assertEquals(0, cmmnRuntimeService.createCaseInstanceQuery().count());
}
}
在 JUnit 4 中,org.flowable.cmmn.engine.test.FlowableCmmnTestCase 可用作父类。它默认使用 flowable.cmmn.cfg.xml 配置文件,如果缺少此类文件,则使用连接 H2 内存数据库的标准 CmmnEngine。 在后台,CmmnTestRunner 用于初始化 CMMN 引擎。请注意下面的示例中如何使用 @CmmnDeployment 注解自动部署案例定义(它将在与测试类相同的文件夹中查找 .cmmn 文件,并期望文件名为<测试类名>.<测试方法名称>.cmmn)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class MyTest extends FlowableCmmnTestCase {
@Test
@CmmnDeployment
public void testSingleHumanTask() {
CaseInstance caseInstance = cmmnRuntimeService.createCaseInstanceBuilder()
.caseDefinitionKey("myCase")
.start();
assertNotNull(caseInstance);
Task task = cmmnTaskService.createTaskQuery().caseInstanceId(caseInstance.getId()).singleResult();
assertEquals("Task 1", task.getName());
assertEquals("JohnDoe", task.getAssignee());
cmmnTaskService.complete(task.getId());
assertEquals(0, cmmnRuntimeService.createCaseInstanceQuery().count());
}
}
此外,使用 FlowableCmmnRule 并允许设置自定义配置:
1
2
3
4
5
6
7
8
9
10
@Rule
public FlowableCmmnRule cmmnRule = new FlowableCmmnRule("org/flowable/custom.cfg.xml")
@Test
@CmmnDeployment
public void testSomething() {
// ...
assertThat((String) cmmnRule.getCmmnRuntimeService().getVariable(caseInstance.getId(), "test"), containsString("John"));
// ...
}
4. 整合Spring
不使用spring也可以很好的使用Flowable,在这一章,我们会介绍一些很有用的整合特性。
4.1. CmmnEngineFactoryBean
CmmnEngine 可以配置位一般的spring bean。整合的基点是 org.flowable.cmmn.spring.CmmnEngineFactoryBean 类。这个bean加载CMMN配置文件并创建CMMN引擎。这意味着创建和配置和之前文档 configuration section 是一致的。整合spring,配置文件和引擎的服务类看上去是这样的:
1
2
3
4
5
6
7
<bean id="cmmnEngineConfiguration" class="org.flowable.cmmn.spring.SpringCmmnEngineConfiguration">
...
</bean>
<bean id="cmmnEngine" class="org.flowable.cmmn.spring.CmmnEngineFactoryBean">
<property name="cmmnEngineConfiguration" ref="cmmnEngineConfiguration" />
</bean>
注意 cmmnEngineConfiguration bean现在使用的是 org.flowable.cmmn.spring.SpringCmmnEngineConfiguration 。
4.2. 默认spring配置
以下章节包括数据源(dataSource),事务管理(transactionManager),cmmn引擎(cmmnEngine)以及Flowable引擎各服务。
当将数据源(DataSource)装入 SpringCmmnEngineConfiguration (使用字段"dataSource") 里,Flowable将全局使用 org.springframework.jdbc.datasource.TransactionAwareDataSourceProxy 代理,用来包装传入的数据源。目的是让spring事务很好的管理数据库连接。这意味着您在spring配置里,不需要再代理数据源。尽管也可以将一个 TransactionAwareDataSourceProxy 装入 SpringCmmnEngineConfiguration ,但是再这种情况下,CMMN引擎不会再次包装该数据源。
确保在使用在spring配置中声明 TransactionAwareDataSourceProxy 时,不要使用在spring事务代管下的数据源(比如 DataSourceTransactionManager 需要未被代理的dataSource)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.0.xsd">
<bean id="dataSource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<property name="driverClass" value="org.h2.Driver" />
<property name="url" value="jdbc:h2:mem:flowable;DB_CLOSE_DELAY=1000" />
<property name="username" value="sa" />
<property name="password" value="" />
</bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="cmmnEngineConfiguration" class="org.flowable.cmmn.spring.SpringCmmnEngineConfiguration">
<property name="dataSource" ref="dataSource" />
<property name="transactionManager" ref="transactionManager" />
<property name="databaseSchemaUpdate" value="true" />
</bean>
<bean id="cmmnEngine" class="org.flowable.cmmn.spring.CmmnEngineFactoryBean">
<property name="cmmnEngineConfiguration" ref="cmmnEngineConfiguration" />
</bean>
<bean id="cmmnRepositoryService" factory-bean="cmmnEngine" factory-method="getCmmnRepositoryService" />
<bean id="cmmnRuntimeService" factory-bean="cmmnEngine" factory-method="getCmmnRuntimeService" />
<bean id="cmmnTaskService" factory-bean="cmmnEngine" factory-method="getCmmnTaskService" />
<bean id="cmmnHistoryService" factory-bean="cmmnEngine" factory-method="getCmmnHistoryService" />
<bean id="cmmnManagementService" factory-bean="cmmnEngine" factory-method="getCmmnManagementService" />
...
首先,application context(spring容器上下文)可以使用任何spring的配置方式(比如:xml,@Configuration等)。这个示例使用的XML配置方式。
1
2
ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext(
"org/flowable/cmmn/examples/spring/SpringIntegrationTest-context.xml");
测试时这样使用:
1
2
@ContextConfiguration(
"classpath:org/flowable/cmmn/spring/test/SpringIntegrationTest-context.xml")
4.3. 表达式
使用CmmnEngineFactoryBean,所有的spring bean在CMMN流程中的表达式默认都是可见的。可以在配置SpringCmmnEngineConfiguration的beans(类型Map)属性,限制表达式中使用的bean。下面的示例是暴露了单独的名为printer的bean。 * 如果没有需要暴露给表达式的bean,配置 beans属性位一个空map。当不设置 beans 属性时,所有spring容器里的bean都是可用的。 *
1
2
3
4
5
6
7
8
9
10
<bean id="cmmnEngineConfiguration" class="org.flowable.cmmn.spring.SpringCmmnEngineConfiguration">
...
<property name="beans">
<map>
<entry key="printer" value-ref="printer" />
</map>
</property>
</bean>
<bean id="printer" class="org.flowable.cmmn.examples.spring.Printer" />
将可以使用的bean暴露给表达式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
...
<case id="myCase">
<casePlanModel id="myPlanModel" name="My CasePlanModel">
<planItem id="planItem1" name="Task One" definitionRef="serviceTask" />
<planItem id="planItem2" name="The Case" definitionRef="task">
<entryCriterion sentryRef="sentry1" />
</planItem>
<sentry id="sentry1">
<planItemOnPart sourceRef="planItem1">
<standardEvent>complete</standardEvent>
</planItemOnPart>
</sentry>
<task id="serviceTask" flowable:type="java" flowable:expression="${printer.printMessage(var1)}" flowable:resultVariableName="customResponse" />
<task id="task" name="The Task" isBlocking="true" />
</casePlanModel>
</case>
+Printer+ 代码:
1
2
3
4
5
6
public class Printer {
public void printMessage(String var) {
System.out.println("hello " + var);
}
}
Spring配置是这样的(如上所示):
1
2
3
4
5
6
<beans>
...
<bean id="printer" class="org.flowable.cmmn.examples.spring.Printer" />
</beans>
4.4. 自动部署资源
Spring integration also has a special feature for deploying resources. In the CMMN engine configuration, you can specify a set of resources. When the CMMN engine is created, all those resources will be scanned and deployed. There is filtering in place that prevents duplicate deployments. Only when the resources have actually changed will new deployments be deployed to the Flowable DB. This makes sense in a lot of use cases, where the Spring container is rebooted frequently (for example, testing).
整合spring,部署资源有一个独有的特性。CMMN引擎配置中可以定义很多资源。当CMMN引擎创建,这些资源将被扫描,发布。这个过程中将过滤重复发布的资源。当资源产生改变,将重新发布对应资源到数据库。这个在频繁重启的时候是很有意义的(比如测试时)。
Here’s an example:
请看示例:
1
2
3
4
5
6
7
8
9
<bean id="cmmnEngineConfiguration" class="org.flowable.cmmn.spring.SpringCmmnEngineConfiguration">
...
<property name="deploymentResources"
value="classpath*:/org/flowable/cmmn/spring/test/autodeployment/autodeploy.*.cmmn" />
</bean>
<bean id="cmmnEngine" class="org.flowable.cmmn.spring.CmmnEngineFactoryBean">
<property name="cmmnEngineConfiguration" ref="cmmnEngineConfiguration" />
</bean>
以上配置默认将匹配到资源当作同一次发布(deployment)到Flowable引擎。没有更改的资源对整个发布生效。某些情况下,这可能不是所需要的。举个例子,这些发布里仅仅有一个资源文件有改动,那么发布(deployment)包含的所有资源都会被重新发布,导致实际没有变更的事例定义会产生新的版本。
针对以上的问题,可以更改 SpringCmmnEngineConfiguration, deploymentMode , 整个属性定义了如何判断资源将被部署。默认情况下该属性有一下三个选项:
-
default: 默认配置,将所有资源视为一组,当作同一发布. -
single-resource: 单独发布,将所有分开的资源每一个当作一组发布。适用于分开发布所有流程定义,当有所改变时,只有改变的事务定义会产生新的版本号。 -
resource-parent-folder: 目录发布,将同一文件夹下的资源文件视为一组,作为同一文件发布。适用于将不同的部署于大多数资源文件,但是依然会将共享文件夹的资源文件视为一组。下面的示例代码为使用+single-resource+ 配置deploymentMode:
1
2
3
4
5
6
<bean id="cmmnEngineConfiguration"
class="org.flowable.cmmn.spring.SpringCmmnEngineConfiguration">
...
<property name="deploymentResources" value="classpath*:/flowable/*.cmmn" />
<property name="deploymentMode" value="single-resource" />
</bean>
除了以上列举的3个值来配置 deploymentMode, 您也可以自定义规则去检测发布,创建 SpringCmmnEngineConfiguration 的子类,覆盖 getAutoDeploymentStrategy(String deploymentMode) 方法。该方法确定 deploymentMode 将使用哪种策略。
4.5. 单元测试
整合spring 使用 Flowable testing facilities 可以很容易去测试业务事例。 以下示例是经典的Spring-based JUnit 4或5的测试用例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
@ExtendWith(FlowableCmmnSpringExtension.class)
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = CmmnSpringJunitJupiterTest.TestConfiguration.class)
class MyBusinessCaseTest {
@Autowired
private CmmnRepositoryService cmmnRepositoryService;
@Autowired
private CmmnRuntimeService cmmnRuntimeService;
@Test
@CmmnDeployment
public void simpleCaseTest() {
CaseInstance caseInstance = cmmnRuntimeService.createCaseInstanceBuilder()
.caseDefinitionKey("simpleCase")
.variable("var1", "John Doe")
.start();
Assertions.assertNotNull(caseInstance);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class MyBusinessCaseTest {
@Rule
public FlowableCmmnRule cmmnRule = new FlowableCmmnRule("org/flowable/spring/test/el/SpringBeanTest-context.xml");
@Test
public void simpleCaseTest() {
cmmnRule.getCmmnRepositoryService().createDeployment().addClasspathResource("org/flowable/spring/test/el/springExpression.cmmn").deploy();
CmmnRuntimeService cmmnRuntimeService = cmmnRule.getCmmnRuntimeService();
CaseInstance caseInstance = cmmnRuntimeService.createCaseInstanceBuilder()
.caseDefinitionKey("myCase")
.variable("var1", "John Doe")
.start();
Assert.assertNotNull(caseInstance);
}
}
5. 部署
5.1. 外部资源
案例定义位于Flowable 数据库中。当在Flowable 配置文件使用Service Tasks或Spring Beans时,这些案例定义可以引用委托类来处理。 这些类和Spring配置文件,必须可以用于所有可能执行案例定义的CMMN引擎。
5.1.1. JAVA 类
在案例定义中使用的所有自定义类(例如,服务任务中使用的PlanItemJavaDelegates)都应该在启动案例实例时,配置在引擎的类路径上。
但是,在部署案例定义期间,这些类不必配置在类路径上。也就是说在部署新的案例定义时,您的委托类不必位于类路径上,例如:当您使用演示安装程序并要添加自定义类时,应该将包含类的JAR添加到“flowable-task”或“flowable-rest” webapp lib中。别忘了还要包括自定义类(如果有的话)的依赖项。或者您也可以将依赖项配置在Tomcat安装的libraries目录中,$tomcat.home/lib(或其他Web容器的类似位置)。
5.1.2. 从案例实例中使用SpringBeans
当在表达式或脚本使用SpringBean时,在执行案例定义时,这些bean必须对引擎可用。如果您正在构建自己的webapp,并按照 “Spring集成”章节 中的相关章节描述,在您的应用上下问文中配置CMMN引擎,那这很简单。但请记住,如果您使用"Flowable task"和"Flowable rest" webapps,那么也应该使用该上下文对其进行更新。
5.2. 案例定义的版本管理
CMMN没有版本控制的概念,这实际上很好,因为可执行CMMN文件可能作为开发项目的一部分存在于版本控制系统库中(如Subversion、Git或Mercurial)。但是,案例定义的版本是作为部署的一部分在引擎中创建的。在部署过程中,flowable将为CaseDefinition分配一个版本,然后将其存储在flowable数据库中
对于部署中的每个案例定义,执行以下步骤初始化属性键、版本、名称和ID:
-
XML文件中的案例定义+id+属性,用作案例定义+key+属性。
-
XML文件中的案例定义+名称+属性用作案例定义+名称+属性。如果未指定名称属性,则使用id属性作为名称。
-
第一次部署具有特定密钥的案例时,将分配版本1。对于具有相同键的案例定义的所有后续部署版本,版本将设置为比当前部署的最高版本高1。key属性用于区分大小写定义。
以下面的例子为例
1
2
3
<definitions id="myDefinitions" >
<case id="myCase" name="My important case" >
...
部署此案例定义时,数据库中的案例定义将看起来像这样
| id | key | name | version |
|---|---|---|---|
676 |
myCase |
My important case |
1 |
假设我们现在部署相同案例的更新版本(例如,更改一些人工任务),但案例定义的ID保持不变。案例定义表现在将包含以下条目:
| id | key | name | version |
|---|---|---|---|
676 |
myCase |
My important case |
1 |
870 |
myCase |
My important case |
2 |
当调用RuntimeService.CreateCaseInstanceBuilder().CaseDefinitionKey(“MyCase”).Start()时,它现在将在版本2中使用案例定义,因为这是案例定义的最新版本。
如果我们像下面定义的那样创建第二个案例并将其部署到Flowable,那么第三行将添加到表中。
1
2
3
<definitions id="myNewDefinitions" >
<case id="myNewCase" name="My important case" >
...
这个表看起来像这样:
| id | key | name | version |
|---|---|---|---|
676 |
myCase |
My important case |
1 |
870 |
myCase |
My important case |
2 |
1033 |
myNewCase |
My important case |
1 |
请注意:新案例的关键与第一个案例有何不同?尽管名称是相同的(我们可能也该更改它),但在区分大小写时,Flowable只考虑ID属性。因此,新案例会与版本1一起部署。
5.3. 分类
部署和案例定义都有用户定义的类别。案例定义类别是用CMMN XML中的“targetNamespace”属性的值初始化的:<definitions…targetNamespace=“您定义的类别”…
部署类别也可以在API中指定,如下所示:
1
2
3
4
5
repositoryService
.createDeployment()
.category("yourCategory")
...
.deploy();
6. CMMN 1.1
6.1. 什么是 CMMN?
案例管理模型和标记法是由对象管理组织(Object Management Group,缩写为OMG)为了表示案例模型而建立的标准规范.
Flowable 包含:
-
一个基于CMMN1.1的模型设计器用来创建案例模型
-
一个JAVA引擎用来导入并运行CMMN1.1案例模型
-
一个动态前端页面用来执行案例模型,并允许用户查看并完成相关任务和对应表单
6.2. 基础概念和术语
以下内容展示了一个简单的CMMN1.1图:
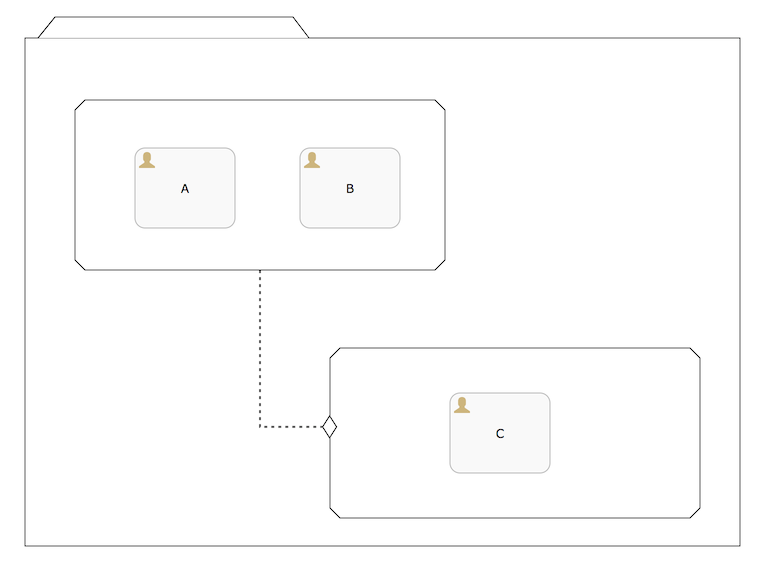
一个 案例模型 通常被看作一个包含所有的案例元素的 文件夹. 每个案例模型包含一个 计划模型 ,其他所有的元素放在该计划模型内部.
一个计划模型中所有元素被称为 计划项. 每个计划项都一个类型及运行时相关配置项的定义.例如,上图中,有三个人工任务和一个里程碑.其他的计划项分别有 流程任务、案例任务和阶段.
当把一个案例模型在Flowable CMMN引擎上部署完成后, 很可能就直接启动一个基于此模型的实例. 其中的定义的计划项同样也会产成运行时的实例并且暴露出来,通过使用Flowable API可以查询得到. 计划项实例 拥有基于CMMN 1.1规范定义的生命周期状态, 并且是整个引擎工作的核心. 详细内容请查阅 CMMN1.1规范的8.4.2部分.
计划项可以拥有 哨兵: 当使用哨兵守卫它的激活, 这个计划项相当于拥有入口凭证.这些凭证明确了触发哨兵需要满足的条件.例如,在上图中,里程碑在一个案例实例启动后为可用状态,但是当人工任务A和人工任务B都完成后,该里程碑状态由可用状态变成活跃状态.注意守卫可以在它的条件中使用不可见的复杂表达式,以便完成更多复杂的功能.同样,也可以拥有多个守卫,只需满足一个哨兵就可以出发状态的转变.
计划项和计划模型也可以拥有退出凭证的哨兵,其明确了从对应计划项退出的条件.在上图中,当人工任务C完成后,整个计划模型(包括此刻所有活跃状态的子元素)将会退出.
CMMN 1.1在XSD中定义作为规范一部分的XML标准格式. 已供参阅, 下面展示的XML代表了上述例子的案例图.
一些结论:
-
XML中的四个计划项通过使用 definitionRef 属性关联它们自身的定义. 实际的声明是在底部的 casePlanModel 元素
-
拥有进入或退出凭证的计划项关联一个 sentry 哨兵(而不是反过来)
-
XML也包含可见案例图的信息(x 和 y坐标, 宽度和高度等等),在以下展示中已省略. 当使用其他 CMMN 1.1 模型工具用来保存正确的可视化案例图时,这些信息是重要的.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/CMMN/20151109/MODEL"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:flowable="http://flowable.org/cmmn"
xmlns:cmmndi="http://www.omg.org/spec/CMMN/20151109/CMMNDI"
xmlns:dc="http://www.omg.org/spec/CMMN/20151109/DC"
xmlns:di="http://www.omg.org/spec/CMMN/20151109/DI"
targetNamespace="http://www.flowable.org/casedef">
<case id="simpleExample" name="Simple Example">
<casePlanModel id="casePlanModel" name="My Case">
<planItem id="planItem1" name="Human task A"
definitionRef="sid-88199E7C-7655-439C-810B-8849FC52D3EB"></planItem>
<planItem id="planItem2" name="Milestone One"
definitionRef="sid-8BF8A774-A8A7-4F1A-95CF-1E0D61EE5A47">
<entryCriterion id="sid-62CC4A6D-B29B-4129-93EA-460253C45CDF"
sentryRef="sentry1"></entryCriterion>
</planItem>
<planItem id="planItem3" name="Human task B"
definitionRef="sid-A1FB8733-0DBC-4B38-9830-CBC4D0C4B802"></planItem>
<planItem id="planItem4" name="Human task C"
definitionRef="sid-D3970AFC-7391-4BA7-95BA-51C64D2F41E9"></planItem>
<sentry id="sentry1">
<planItemOnPart id="sentryOnPart1" sourceRef="planItem1">
<standardEvent>complete</standardEvent>
</planItemOnPart>
<planItemOnPart id="sentryOnPart2" sourceRef="planItem3">
<standardEvent>complete</standardEvent>
</planItemOnPart>
</sentry>
<sentry id="sentry2">
<planItemOnPart id="sentryOnPart3" sourceRef="planItem4">
<standardEvent>complete</standardEvent>
</planItemOnPart>
</sentry>
<humanTask id="sid-88199E7C-7655-439C-810B-8849FC52D3EB"
name="Human task A"></humanTask>
<milestone id="sid-8BF8A774-A8A7-4F1A-95CF-1E0D61EE5A47"
name="Milestone One"></milestone>
<humanTask id="sid-A1FB8733-0DBC-4B38-9830-CBC4D0C4B802"
name="Human task B"></humanTask>
<humanTask id="sid-D3970AFC-7391-4BA7-95BA-51C64D2F41E9"
name="Human task C"></humanTask>
<exitCriterion id="sid-422626DB-9B40-49D8-955E-641AB96A5BFA"
sentryRef="sentry2"></exitCriterion>
</casePlanModel>
</case>
<cmmndi:CMMNDI>
<cmmndi:CMMNDiagram id="CMMNDiagram_simpleExample">
...
</cmmndi:CMMNDiagram>
</cmmndi:CMMNDI>
</definitions>
6.3. 程序示例
在这个小节, 我们将会用代码构建并执行一个简单的案例模型, 通过在命令行中调用Flowable CMMN engine的Java API.
在这个案例模型中, 我们将构建一个简化的有两个阶段的 employee onboarding 案例: 两个时期分别在的员工入职前后.第一个阶段,HR部门中的某个人将会完成相关任务;第二个阶段,该员工完成它们.同时,在任何时间,该试用员工可以拒绝这份工作并且停止这个实例.
注意, 只有 stages and human tasks 被用到. 在真实案例模型中, 很可能会有其他类型的计划项,比如里程碑, 嵌套stage, 自动化任务等等.
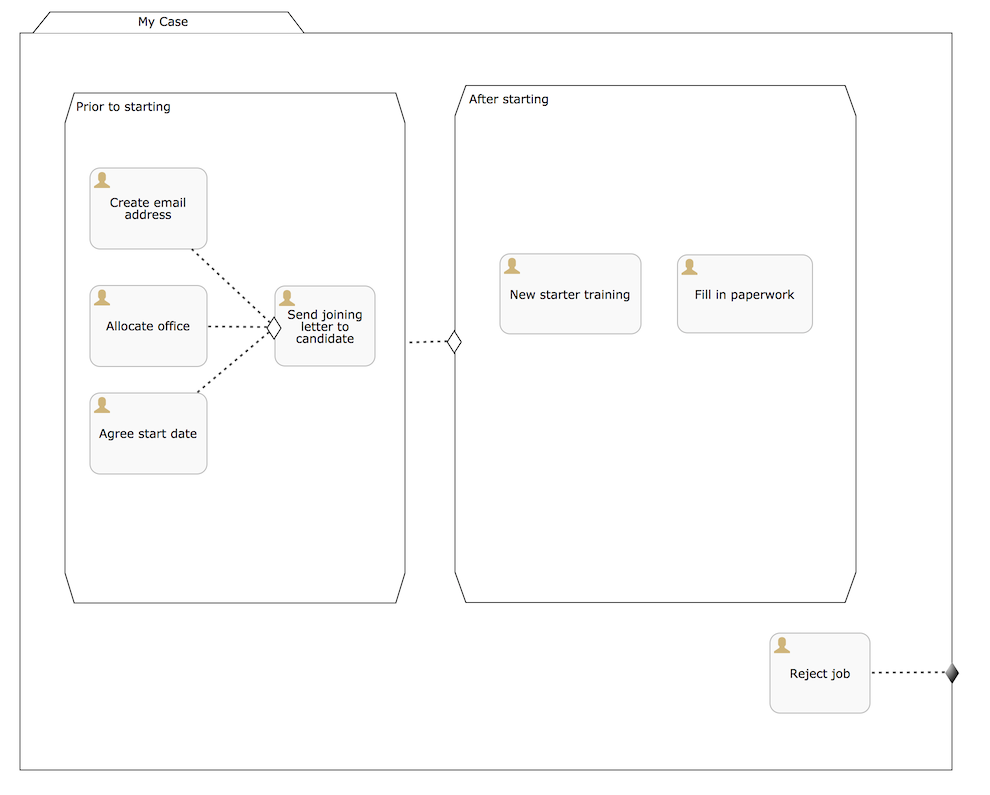
这个案例模型的XML如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/CMMN/20151109/MODEL"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:flowable="http://flowable.org/cmmn"
xmlns:cmmndi="http://www.omg.org/spec/CMMN/20151109/CMMNDI"
xmlns:dc="http://www.omg.org/spec/CMMN/20151109/DC"
xmlns:di="http://www.omg.org/spec/CMMN/20151109/DI"
targetNamespace="http://www.flowable.org/casedef">
<case id="employeeOnboarding" name="Simple Example">
<casePlanModel id="casePlanModel" name="My Case">
<planItem id="planItem5" name="Prior to starting"
definitionRef="sid-025D29E8-BA9B-403D-A684-8C5B52185642"></planItem>
<planItem id="planItem8" name="After starting"
definitionRef="sid-8459EF32-4F4C-4E9B-A6E9-87FDC2299044">
<entryCriterion id="sid-50B5F12D-FE75-4D05-9148-86574EE6C073"
sentryRef="sentry2"></entryCriterion>
</planItem>
<planItem id="planItem9" name="Reject job"
definitionRef="sid-134E885A-3D58-417E-81E2-66A3E12334F9"></planItem>
<sentry id="sentry2">
<planItemOnPart id="sentryOnPart4" sourceRef="planItem5">
<standardEvent>complete</standardEvent>
</planItemOnPart>
</sentry>
<sentry id="sentry3">
<planItemOnPart id="sentryOnPart5" sourceRef="planItem9">
<standardEvent>complete</standardEvent>
</planItemOnPart>
</sentry>
<stage id="sid-025D29E8-BA9B-403D-A684-8C5B52185642" name="Prior to starting">
<planItem id="planItem1" name="Create email address"
definitionRef="sid-EA434DDD-E1BE-4AC1-8520-B19ACE8782D2"></planItem>
<planItem id="planItem2" name="Allocate office"
definitionRef="sid-505BA223-131A-4EF0-ABAD-485AEB0F2C96"></planItem>
<planItem id="planItem3" name="Send joining letter to candidate"
definitionRef="sid-D28DBAD5-0F5F-45F4-8553-3381199AC45F">
<entryCriterion id="sid-4D88C79D-8E31-4246-9541-A4F6A5720AC8"
sentryRef="sentry1"></entryCriterion>
</planItem>
<planItem id="planItem4" name="Agree start date"
definitionRef="sid-97A72C46-C0AD-477F-86DD-85EF643BB97D"></planItem>
<sentry id="sentry1">
<planItemOnPart id="sentryOnPart1" sourceRef="planItem1">
<standardEvent>complete</standardEvent>
</planItemOnPart>
<planItemOnPart id="sentryOnPart2" sourceRef="planItem2">
<standardEvent>complete</standardEvent>
</planItemOnPart>
<planItemOnPart id="sentryOnPart3" sourceRef="planItem4">
<standardEvent>complete</standardEvent>
</planItemOnPart>
</sentry>
<humanTask id="sid-EA434DDD-E1BE-4AC1-8520-B19ACE8782D2"
name="Create email address"
flowable:candidateGroups="hr"></humanTask>
<humanTask id="sid-505BA223-131A-4EF0-ABAD-485AEB0F2C96"
name="Allocate office"
flowable:candidateGroups="hr"></humanTask>
<humanTask id="sid-D28DBAD5-0F5F-45F4-8553-3381199AC45F"
name="Send joining letter to candidate"
flowable:candidateGroups="hr"></humanTask>
<humanTask id="sid-97A72C46-C0AD-477F-86DD-85EF643BB97D"
name="Agree start date"
flowable:candidateGroups="hr"></humanTask>
</stage>
<stage id="sid-8459EF32-4F4C-4E9B-A6E9-87FDC2299044"
name="After starting">
<planItem id="planItem6" name="New starter training"
definitionRef="sid-DF7B9582-11A6-40B4-B7E5-EC7AC6029387"></planItem>
<planItem id="planItem7" name="Fill in paperwork"
definitionRef="sid-7BF2B421-7FA0-479D-A8BD-C22EBD09F599"></planItem>
<humanTask id="sid-DF7B9582-11A6-40B4-B7E5-EC7AC6029387"
name="New starter training"
flowable:assignee="${potentialEmployee}"></humanTask>
<humanTask id="sid-7BF2B421-7FA0-479D-A8BD-C22EBD09F599"
name="Fill in paperwork"
flowable:assignee="${potentialEmployee}"></humanTask>
</stage>
<humanTask id="sid-134E885A-3D58-417E-81E2-66A3E12334F9" name="Reject job"
flowable:assignee="${potentialEmployee}"></humanTask>
<exitCriterion id="sid-18277F30-E146-4B3E-B3C9-3F1E187EC7A8"
sentryRef="sentry3"></exitCriterion>
</casePlanModel>
</case>
</definitions>
首先, 创建一个新的工程, 添加 flowable-cmmn-engine 依赖(这里展示了Maven), H2 数据库依赖也要添加, 后续将会使用 H2 作为内嵌的数据库.
1
2
3
4
5
6
7
8
9
10
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-cmmn-engine</artifactId>
<version>${flowable.version}</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>${h2.version}</version>
</dependency>
The Flowable CMMN API 包括了其他的 Flowable APIs 和相关概念. 同样,熟悉 BPMN 或者 DMN APIs的人很容易上手.和其他引擎一样, 第一行代码是创建一个 Cmmn引擎. 这里,默认的配置将会使用 H2作为内存数据库:
1
2
3
4
5
6
public class Main {
public static void main(String[] args) {
CmmnEngine cmmnEngine
= new StandaloneInMemCmmnEngineConfiguration().buildCmmnEngine();
}
}
注意_CmmnEngineConfiguration_ 提供了很多配置项来调整 CMMN引擎的设置.
把上述 XML 放入一个文件中, 例如 my-case.cmmn (or .cmmn.xml). 对于Maven工程, 应该放在 src/main/resources 文件夹中.
为了使引擎感知当前案例模型, 它首先需要被部署 deployed. 这个工作由 the CmmnRepositoryService 完成:
1
2
3
4
CmmnRepositoryService cmmnRepositoryService = cmmnEngine.getCmmnRepositoryService();
CmmnDeployment cmmnDeployment = cmmnRepositoryService.createDeployment()
.addClasspathResource("my-case.cmmn")
.deploy();
当部署XML时, 会返回一个 CmmnDeployment. 一个 deployment 包含多个案例模型和目标. 一个明确的案例模型定义被存储成一个案例定义 CaseDefinition. 这可以通过执行 CaseDefinitionQuery 案例定义查询 来验证:
1
2
List<CaseDefinition> caseDefinitions = cmmnRepositoryService.createCaseDefinitionQuery().list();
System.out.println("Found " + caseDefinitions.size() + " case definitions");
当在引擎中拥有一个案例定义后, 现在可以启动一个对应 CaseInstance 案例实例. 要么使用查询后的结果并传递给下面的代码片段中, 要么直接使用 the case definition的key(如下所示).
注意当启动 CaseInstance, 我们也传递了 potentialEmployee 作为一个标记, 这个变量之后会被用作人工任务的指派(see the assignee="${potentialEmployee}" attribute on human tasks)
1
2
3
4
5
CmmnRuntimeService cmmnRuntimeService = cmmnEngine.getCmmnRuntimeService();
CaseInstance caseInstance = cmmnRuntimeService.createCaseInstanceBuilder()
.caseDefinitionKey("employeeOnboarding")
.variable("potentialEmployee", "johnDoe")
.start();
当 CaseInstance 启动后, 引擎将决定哪一个计划项应该被激活:
-
第一个阶段没有入口凭证, 所以它会被激活
-
第一个阶段的子人工任务没有入口凭证, 所以它们三个也预计被激活
在运行时, 计划项被当做 PlanItemInstances, 可以使用 CmmnRuntimeService 查询获取:
1
2
3
4
5
6
7
8
List<PlanItemInstance> planItemInstances = cmmnRuntimeService.createPlanItemInstanceQuery()
.caseInstanceId(caseInstance.getId())
.orderByName().asc()
.list();
for (PlanItemInstance planItemInstance : planItemInstances) {
System.out.println(planItemInstance.getName());
}
打印如下:
After starting Agree start date Allocate office Create email address Prior to starting Reject job Send joining letter to candidate
上述打印结果中有些事情可能出乎意料:
-
stages 也是属于 计划项, 同样被当做 PlanItemInstance. 注意当调用 .getStageInstanceId() ,子计划项实例也会拥有stage作为父类.
-
Send joining letter to candidate 也在返回结果集中.原因是因为依据 CMMN 1.1 规范, 这个计划项实例是出于可用状态, 而不是处于活跃状态.
进一步, 修改上述代码:
1
2
3
4
5
for (PlanItemInstance planItemInstance : planItemInstances) {
System.out.println(planItemInstance.getName()
+ ", state=" + planItemInstance.getState()
+ ", parent stage=" + planItemInstance.getStageInstanceId());
}
现在输出如下:
After starting, state=available, parent stage=null Agree start date, state=active, parent stage=fe37ac97-b016-11e7-b3ad-acde48001122 Allocate office, state=active, parent stage=fe37ac97-b016-11e7-b3ad-acde48001122 Create email address, state=active, parent stage=fe37ac97-b016-11e7-b3ad-acde48001122 Prior to starting, state=active, parent stage=null Reject job, state=active, parent stage=fe37ac97-b016-11e7-b3ad-acde48001122 Send joining letter to candidate, state=available, parent stage=fe37ac97-b016-11e7-b3ad-acde48001122
为了只显示活跃状态的计划项实例, 查询可以调整并增加 planItemInstanceStateActive() 方法:
1
2
3
4
5
List<PlanItemInstance> planItemInstances = cmmnRuntimeService.createPlanItemInstanceQuery()
.caseInstanceId(caseInstance.getId())
.planItemInstanceStateActive()
.orderByName().asc()
.list();
现在输出如下:
Agree start date Allocate office Create email address Prior to starting Reject job
当然, PlanItemInstance 是 低级别的表示, 但是每个计划项也拥有一个 plan item definition 明确其类型. 在这个例子中, 我们只有 human tasks.通过使用 计划项实例 来影响整个 案例实例, (比如, CmmnRuntimeService.triggerPlanItemInstance(String planItemInstanceId)).然而, 交互最有可能通过实际计划项定义的结果发生: 比如这里的人工任务.
任务的查询方法和BPMN 引擎一样, (实际上, 任务服务是一个共享的组件, BPMN或者CMMN创建的任务都可以通过各自引擎查询得到):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
CmmnTaskService cmmnTaskService = cmmnEngine.getCmmnTaskService();
List<Task> hrTasks = cmmnTaskService.createTaskQuery()
.taskCandidateGroup("hr")
.caseInstanceId(caseInstance.getId())
.orderByTaskName().asc()
.list();
for (Task task : hrTasks) {
System.out.println("Task for HR : " + task.getName());
}
List<Task> employeeTasks = cmmnTaskService.createTaskQuery()
.taskAssignee("johndoe")
.orderByTaskName().asc()
.list();
for (Task task : employeeTasks) {
System.out.println("Task for employee: " + task);
}
上述输出:
Task for HR : Agree start date Task for HR : Allocate office Task for HR : Create email address Task for employee: Reject job
当HR的三个任务都完成, 给求职者发送入职信的任务应该是可用的:
1
2
3
4
5
6
7
8
9
10
11
12
13
for (Task task : hrTasks) {
cmmnTaskService.complete(task.getId());
}
hrTasks = cmmnTaskService.createTaskQuery()
.taskCandidateGroup("hr")
.caseInstanceId(caseInstance.getId())
.orderByTaskName().asc()
.list();
for (Task task : hrTasks) {
System.out.println("Task for HR : " + task.getName());
}
事实上, 预期的任务现在被创建了:
Task for HR : Send joining letter to candidate
完成这个任务,案例实例将进入第二个阶段, 同时第一阶段的哨兵的条件得到满足. 'Reject job’任务被程序自动创建, 并且指派给员工的两个任务也被创建:
1
2
3
Task for employee: Fill in paperwork
Task for employee: New starter training
Task for employee: Reject job
完成所有任务将结束整个案例实例:
List<Task> tasks = cmmnTaskService.createTaskQuery().caseInstanceId(caseInstance.getId()).listPage(0, 1);
while (!tasks.isEmpty()) {
cmmnTaskService.complete(tasks.get(0).getId());
tasks = cmmnTaskService.createTaskQuery()
.caseInstanceId(caseInstance.getId())
.listPage(0, 1);
}
当执行案例实例时, 引擎也会保存历史信息, 这可以通过查询API获取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CmmnHistoryService cmmnHistoryService = cmmnEngine.getCmmnHistoryService();
HistoricCaseInstance historicCaseInstance = cmmnHistoryService.createHistoricCaseInstanceQuery()
.caseInstanceId(caseInstance.getId())
.singleResult();
System.out.println("Case instance execution took "
+ (historicCaseInstance.getEndTime().getTime() - historicCaseInstance.getStartTime().getTime()) + " ms");
List<HistoricTaskInstance> historicTaskInstances = cmmnHistoryService.createHistoricTaskInstanceQuery()
.caseInstanceId(caseInstance.getId())
.orderByTaskCreateTime().asc()
.list();
for (HistoricTaskInstance historicTaskInstance : historicTaskInstances) {
System.out.println("Task completed: " + historicTaskInstance.getName());
}
输出如下:
Case instance execution took 149 ms Task completed: Reject job Task completed: Agree start date Task completed: Allocate office Task completed: Create email address Task completed: Send joining letter to candidate Task completed: New starter training Task completed: Fill in paperwork
案例执行相关的历史数据以特殊的结构被收集, 比如 Tasks (上面所见的), milestones, cases, variables and 一般的 plan items. 这个数据作为运行时数据被持久化, 但是不会在实例结束后被删除.访问历史数据可以通过 CmmnHistoryService 的相关API
当然, 这只是Flowable CMMN Engine所有可用的APIs中的一小部分,请查阅其他章节了解更多详情
6.4. CMMN 1.1 Constructs
这个小节 覆盖了 Flowable支持的 CMMN 1.1设计, 同时也是对 CMMN 1.1 标准的拓展
下述设计, 除了哨兵和item 控制, 都是依据 CMMN规范中的计划项作为参考.它们实例执行的历史数据可用通过 CmmnHistoryService 使用 org.flowable.cmmn.api.history.HistoricPlanItemInstanceQuery 方法获取.
6.4.1. 阶段
一个 stage 被看作一组计划项的集合, 它通常用于在案例实例中定义"阶段"
一个 stage 本事也是计划项, 也拥有进入和退出凭证. 计划项以及它包含的计划项只有在计入活跃状态才可用, stage 可以内嵌在其他stage中. A stage is visualized as a rectangle with angled corners:
a stage 可以看作是一个有尖角的矩形
6.4.2. 任务
一个手动任务, 意味着它将在引擎外部发生.
Properties:
-
name: 表达式将会在运行时被解析当做任务名称
-
blocking: 布尔值决定是否任务被阻塞
-
blockingExpression: 表达式 计算成布尔值决定该任务是否被阻塞
如果一个任务是 非阻塞non-blocking, 引擎将在执行时自动完成它. 如果一个任务被阻塞blocking, 这个任务对应的计划项实例会被保持活跃状态active state, 直到以编程方式触发( CmmnRuntimeService.triggerPlanItemInstance(String planItemInstanceId) 方法).
一个任务看作一个圆角矩形:

6.4.3. 人工任务
一个人工任务用作模型化需要人完成的工作, 比如表单. 当引擎抵达一个人工任务, 被指派的人工或组对应的任务列表就会新增加一项.
一个人工任务也是一个计划项, 这意味着除了人工任务本身之外,还创建了一个 PlanItemInstance,并且可以通过 PlanItemInstanceQuery 查询它.
人工任务可以通过 org.flowable.task.api.TaskQuery API 查询.历史数据可以通过 org.flowable.task.api.history.HistoricTaskInstanceQuery 查询.
Properties:
属性:
-
name: 被用作该人工任务的名称
-
blocking: 布尔值决定该任务是否被阻塞
-
blockingExpression: 表达式计算得到布尔值决定任务是否被阻塞
-
assignee : 表达式(可以是静态文本) 决定该任务的指派人
-
owner : 表达式(可以是静态文本)决定该任务的拥有者
-
candidateUsers : 表达式(可以是静态文本)解析成以逗号分隔的字符串,被用作决定该人工任务的候选人列表
-
candidateGroups : 表达式(可以是静态文本)解析成以逗号分隔的字符串,被用作决定该人工任务的候选组列表
-
form key: 表达式决定使用表单的key, 后续通过API访问
-
Due date 过期时间 解析为 java.util.Date or a ISO-8601 date string
-
Priority: 优先级 解析为整型, 可以用来在 TaskQuery API中筛选任务
一个人工任务看作一个圆角矩形, 左上角有一个用户图标

6.4.4. Java 服务任务
服务任务被用作执行自定义逻辑.
自定义逻辑要放在一个实现 org.flowable.cmmn.api.delegate.PlanItemJavaDelegate 接口的类中.
1
2
3
4
5
6
7
8
public class MyJavaDelegate implements PlanItemJavaDelegate {
public void execute(DelegatePlanItemInstance planItemInstance) {
String value = (String) planItemInstance.getVariable("someVariable");
...
}
}
对于一些高级实现,使用 PlanItemJavaDelegate 可能不能覆盖到, CmmnActivityBehavior_可以被使用(类似于 BPMN 引擎中的 _JavaDelegate vs ActivityBehavior)
Properties:
属性:
-
name: 服务任务service task的名称
-
class: 自定义逻辑的Java实现类
-
class fields: 调用自定义逻辑时的传递参数
-
Delegate expression: 表达式解析为一个实现_PlanItemJavaDelegate_接口的类
一个 服务任务service task 看作一个圆角矩形, 左上角有个齿轮图标

====决策任务
一个决策任务调用外部 DMN 决策表,并在case实例中存储结果变量
Properties:
属性:
-
Decision table reference: 相关的需要被执行 DMN 决策表.
通过设置'Throw error if no rules were hit'属性, 当在 DMN 决策表计算过程中没有命中任何规则时, 可能会抛出错误.
一个 服务任务service task 看作一个圆角矩形, 左上角有个表格图标

6.4.5. http请求任务
Http Task http请求任务是 service task 一个开箱即用的实现,被用作调用一个http REST 服务.
Http Task http请求任务包含多个参数来自定义请求和响应. 查阅 BPMN http task documentation 了解更多参数设置的细节
一个 服务任务service task 看作一个圆角矩形, 左上角有个火箭图标

6.4.6. 脚本任务
脚本任务类似 BPMN 中脚本任务, 当一个计划项变成活跃状态, 用来执行一个脚本.
Properties:
属性:
-
name: 表示任务名称
-
type: 任务属性, 必须是"script", 表示该任务类型
-
scriptFormat: 拓展属性 表示脚本语言(例如, javascript, groovy)
-
script: 执行的脚本, 在"script"元素中作为一个string
-
autoStoreVariables: 可选的任务属性标记 (默认: false) 表示脚本中定义的变量是否保存到计划项实例上下文中 (查看下面注意事项note)
-
resultVariableName: 可选的任务属性 明确脚本执行结果保存到计划项实例上下文中对应的名称 (查看下面注意事项note)
一个 服务任务service task 看作一个圆角矩形, 左上角有个脚本图标

1
2
3
4
5
6
7
8
9
10
11
12
13
14
<planItem id="scriptPlanItem" name="Script Plan Item" definitionRef="myScriptTask" />
<task name="My Script Task Item" flowable:type="script" flowable:scriptFormat="JavaScript">
<documentation>Optional documentation</documentation>
<extensionElements>
<flowable:field name="script">
<string>
sum = 0;
for ( i in inputArray ) {
sum += i;
}
</string>
</flowable:field>
</extensionElements>
</task>
Note: scriptFormat 属性值必须符合 JSR-223 (scripting for the Java platform). 默认, JavaScript 包含在每个JDK里, 不需要额外的JAR文件. 如果你想使用另外 (JSR-223 兼容) 脚本引擎, 在classpath中添加对应的Jar文件并使用合适的名称. 例如, Flowable 单元测试 经常使用 Groovy, 因为其语法和 JAVA 相像.
注意Groovy脚本引擎是绑定在groovy-jsr223 JAR, 这样, 必须添加下面的依赖:
1
2
3
4
5
<dependency>
<groupId>org.apache.groovy</groupId>
<artifactId>groovy-jsr223</artifactId>
<version>4.x.x<version>
</dependency>
在脚本任务中, 所有案例变量 variables 都可以通过 PlanItem 实例在脚本中访问.在下面的例子中, 脚本变量 'inputArray' 实际上是一个案例变量variable(一个整型数组)
1
2
3
4
5
6
7
8
<flowable:field name="script">
<string>
sum = 0
for ( i in inputArray ) {
sum += i
}
</string>
</flowable:field>
Note: 通过在脚本中调用 planItemInstance.setVariable("variableName", variableValue), 可以设置计划项实例的变量值.默认不会保存任务变量. 通过设置 autoStoreVariables_属性值为true, 也可以自动保存在脚本中定义的变量(例如, 上述实例中的sum).然而, 最好是不要显示调用 _planItemInstance.setVariable("variableName", variableValue) ,在某些版本的JDK中, 一些脚本语言自动保存变量会不起作用. 查阅 链接 了解更多细节
1<task name="Script Task" flowable:type="script" flowable:scriptFormat="groovy" flowable:autoStoreVariables="false">
The default for this parameter is false, meaning that if the parameter is omitted from the script task definition, all the declared variables will only exist during the duration of the script.
该参数默认是false, 意味着在脚本定义中省略, 所有脚本中声明的变量只会存在于脚本执行过程中.
这是一个在脚本中如何设置变量的例子:
1
2
3
4
5
6
<flowable:field name="script">
<string>
def scriptVar = "test123"
planItemInstance.setVariable("myVar", scriptVar)
</string>
</flowable:field>
以下名称是预留的, 不能被使用: out, out:print, lang:import, context, elcontext.
Note 脚本任务的返回值可以被分配给一个已经存在或者新的计划项实例变量, 通过在脚本任务定义中设置_'flowable:resultVariable'_ 属性值.任何已经存在的相同名称变量的值会被脚本返回值覆盖.当未明确设置返回结果变量名, 脚本的返回值会被忽略.
1
2
3
4
5
<task name="Script Task" flowable:type="script" flowable:scriptFormat="groovy" flowable:resultVariable="myVar">
<flowable:field name="script">
<string>#{echo}</string>
</flowable:field>
</task>
在上述实例中, 当脚本执行结束后, 脚本的返回值( '#{echo}'的解析值)会被设置成名称为 'myVar' 的流程变量值.
6.4.7. 里程碑
里程碑被用作标记到达案例实例中的某个点. 在运行时, 它们被称为 MilestoneInstances , 可以通过调用 CmmnRuntimeService 的 MilestoneInstanceQuery 查询. 也可以通过 CmmnHistoryService 获取一个历史副本.
里程碑也是计划项, 这意味着除了里程碑条目外, PlanItemInstance 同样会被创建, 通过_PlanItemInstanceQuery_ 可以查询到.
Properties:
属性:
-
name: 一个表达式或者静态文本, 决定里程碑名称
里程碑被看作一个圆角矩形(比任务更圆一些)

6.4.8. 案例任务
用例任务用作在一个案例上下文中启动一个子案例. CaseInstanceQuery 有一些选项查询父类案例.
当一个案例任务被阻塞, PlanItemInstance 将会处于活跃状态, 直到子案例全部完成.如果案例任务是非阻塞, 子案例启动后, 计划项实例自动完成.当子案例实例结束对父类没有影响.
Properties:
属性:
-
name: 表达式或静态文本, 决定名称
-
blocking: 布尔值决定任务是否被阻塞
-
blockingExpression: 表达式计算得到布尔值决定任务是否被阻塞
-
Case reference: 案例定义的key, 用来启动一个子实例.可以是一个表达式
一个案例任务看作一个圆角矩形, 左上角有一个case 图标
6.4.9. 流程任务
流程任务被用作在案例上下文中启动一个流程实例
当流程任务被阻塞, PlanItemInstance 将会一直 活跃_active_状态, 直到 流程实例全部完成. 如果流程任务非阻塞, 流程实例任务启动并且计划项实例自动完成, 当流程实例结束对父类没有任何影响.
Properties:
属性:
-
name: 表达式或静态文本, 决定名称
-
blocking: 布尔值决定任务是否被阻塞
-
blockingExpression: 表达式计算得到布尔值决定任务是否被阻塞
-
Process reference: 案例定义的key, 用来启动一个子实例.可以是一个表达式
一个流程任务看作一个圆角矩形, 左上角有个箭头图标

流程任务可以配置为具有内部和外部参数,这些参数的形式是_source/sourceExpression_ and target/targetExpression.
内部参数在当前案例实例上下文内被解析.
-
source value 将把一个case实例变量, 映射成一个流程变量
-
或者, the sourceExpression 允许创建任意值,其中表达式根据case实例解析.
-
target 是流程变量的名称, 是被_source_映射
-
或者, _targetExpression_将被解析成一个 string, 用作流程实例的变量名称.表达式根据case实例上下文解析.
内部参数在当前流程实例(全局)上下文内被解析.
-
The source value will be the process instance variable which value will be mapped to a case variable
-
source value 将把一个流程变量值, 映射成一个case变量
-
或者, the sourceExpression 允许创建任意值,其中表达式根据流程实例解析.
-
target 是流程变量的名称, 是被_source_映射
-
或者, _targetExpression_将被解析成一个 string, 用作case实例的变量名称.表达式根据流程实例(全局)上下文解析.
6.4.10. 凭证
入口凭证 (入口哨兵)
进入凭证构成一个计划项实例的哨兵, 它们由两部分组成:
-
One or more parts that depend on other plan items: these define dependencies on state transitions of other plan items. For example, one human task can depend on the state transition complete of three other human tasks to become active itself
-
一个或者多个部分依赖其他计划项: 它们依赖其他计划项状态的转变.例如一个人工任务取决于另外三个人工任务的完成,才能变成活跃状态.
-
One optional if part or condition: this is an expression that allows the definition of a complex condition *一个可选的如果部分或条件: 允许定义一个复杂条件的表达式
A sentry is satisfied when all its criteria are resolved to true. When a criterion evaluates to true, this is stored and remembered for future evaluations. Note that entry criteria of all plan item instances in the available state are evaluated whenever something changes in the case instance. Multiple sentries are possible on a plan item. However, when one is satisfied, the plan item moves from state available to active.
一个哨兵只有所有凭证解析为 true, 才会满足条件. 当一个凭证被解析为true, 将会被存储以便后续计算. 注意当case实例中发生更改时,将计算处于可用状态的所有计划项实例的入口条件. 多个哨兵可能会用在一个计划项, 然而当一个哨兵满足条件, 该计划项状态会从可用 available 变成活跃 active.
See the section on sentry evaluation for more information.
查阅 the section on sentry evaluation, 了解更多详情.
An entry criterion is visualized as a diamond shape (white color inside) on the border of a plan item:
入口哨兵被看作一个菱形(内部白色),位于计划项边界上:
Exit criterion (exit sentry)
Exit criterion (exit sentry) 出口凭证 (出口哨兵)
Exit criteria form a sentry for a given plan item instance. They consist of two parts:
进入凭证构成一个计划项实例的哨兵, 它们由两部分组成:
-
One or more parts that depend on other plan items: these define dependencies on state transitions of other plan items. For example, one human task can depend on reaching a certain milestone to be automatically terminated
-
一个或者多个部分依赖其他计划项: 它们依赖其他计划项状态的转变.例如一个人工任务取决于另外三个人工任务的完成,才能变成活跃状态.
-
One optional if part or condition: this is an expression that allows a complex condition to be defined *一个可选的如果部分或条件: 允许定义一个复杂条件的表达式
A sentry is satisfied when all its criteria are resolved to true. When a criterion evaluates to true, this is stored and remembered for future evaluations. Note that exit criteria of all plan item instances in the active state are evaluated whenever something changes in the case instance. Multiple sentries are possible on a plan item. However, when one is satisfied, the plan item moves from state active to exit.
一个哨兵只有所有凭证解析为 true, 才会满足条件. 当一个凭证被解析为true, 将会被存储以便后续计算. 注意当case实例中发生更改时,将计算处于可用状态的所有计划项实例的入口条件. 多个哨兵可能会用在一个计划项, 然而当一个哨兵满足条件, 该计划项状态会从活跃 active 变成退出 exit.
See the section on sentry evaluation for more information.
查阅 the section on sentry evaluation 了解更多.
An exit criterion is visualized as a diamond shape (white color inside) on the border of a plan item:
出口哨兵被看作一个菱形(内部黑色),位于计划项边界上:

6.4.11. Event Listeners
6.4.12. Event Listeners 事件监听器
Timer Event Listener
Timer Event Listener 计时器事件监听器
A timer event listener is used when the passing of time needs to be captured in a case model.
计时器事件监听器在一个case模型中被用作捕获时间的传递.
A timer event listener is not a task and has a simpler plan item lifecycle compared to a task: the timer will simply move from available to completed when the event (in this case, the time passing) occurs.
计时器事件监听器不是一个任务, 相比于任务, 拥有更简单的生命周期: 当一个事件(比如, 时间传递)发生时, 计时器简单从可用 available 状态变成完成 completed 状态.
Properties:
属性:
-
Timer expression: an expression that defines when the timer should occur. The following options are possible:
-
Timer expression: 表达式定义计时器何时发生. 以下是可能的使用配置:
-
An expression resolving to a java.util.Date or org.joda.time.DateTime instance (for example, _${someBean.calculateNextDate(someCaseInstanceVariable)})
-
表达式被解析成 a java.util.Date or org.joda.time.DateTime instance (例如, ${someBean.calculateNextDate(someCaseInstanceVariable)})
-
An ISO8601 date
-
ISO8601 格式日期
-
An ISO8601 duration String (for example, PT5H, indicating the timer should fire in 5 hours from instantiation)
-
ISO8601 格式 持续String (例如, PT5H, 表示计时器应在实例化后5小时启动)
-
AN ISO8601 repetition String (for example, R5/PT2H, indicating the timer should fire 5 times, each time waiting 2 hours)
-
ISO8601 循环时间周期 (例如, R5/PT2H, 表示总共触发5次, 每次间隔2小时)
-
A String containing a cron expression
-
cron表达式指定
-
-
Start trigger plan item/event: reference to a plan item in the case model that triggers the start of the timer event listener
-
Start trigger plan item/event: 引用case模型中计划项, 用来触发计时器事件监听器的开始.
Note that setting a start trigger for the timer event listener does not have a visual indicator in the case model, unlike entry/exit criteria on sentries.
注意 设置计时器事件监听器的 start trigger 属性在case 模型中没有可视化指示, 不像入口/出口哨兵的凭证.
A timer event listener is visualized as circle with a clock icon inside:
计时器事件监听器看作一个圆, 里面有一个钟表图标:
User Event Listener
User Event Listener 用户事件监听器
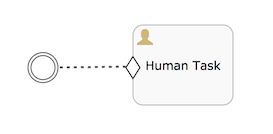
A user event listener can be used when needing to capture a user interaction that directly influences a case state, instead of indirectly via impacting variables or information in the case. A typical use case for a user event listener are buttons in a UI that a user can click to drive the state of the case instance. When the event is triggered an Occur event is thrown to which sentries can listener to. Like timer event listeners, it has a much simpler lifecycle that a task.
一个用户事件监听器被用作捕获一个直接影响案例状态而不是间接影响变量或者案例信息的用户交互. 一个典型的例子就是界面的按钮,用户点击后改变case实例的状态. 当 事件被触发, Occur event会被抛出, 并且被哨兵所捕获. 类似计时器事件监听器, 相比任务,它也有一个更为简单的生命周期.
User event listeners can be queried using the org.flowable.cmmn.api.runtime.UserEventListenerInstanceQuery. Such a query can be created by calling the cmmnRuntimeService.createUserEventListenerInstanceQuery() method. Note that a user event listener is also a plan item instance, which means it can also be queried through the org.flowable.cmmn.api.runtime.PlanItemInstanceQuery API.
用户事件监听器可以使用 org.flowable.cmmn.api.runtime.UserEventListenerInstanceQuery 查询. 类似调用 the cmmnRuntimeService.createUserEventListenerInstanceQuery() 方法. 注意:也是一个计划项实例, 意味着也可以通过 the org.flowable.cmmn.api.runtime.PlanItemInstanceQuery API 查询.
A user event listener can be completed by calling the cmmnRuntimeService.completeUserEventListenerInstance(id) method.
用户事件监听器可以通过调用 cmmnRuntimeService.completeUserEventListenerInstance(id) 方法来完成.
Generic Event Listener
Generic Event Listener 一般事件监听器
A generic event listener is used to typically model a programmatic interaction (e.g. a external system that calls out to change something in a case instance).
一般事件监听器通常被用作编程交互建模(例如, 一个外部系统在一个case实例中调用来更改某些东西)
The API to retrieve and complete these event listeners is on the CmmnRuntimeService:
通过 CmmnRuntimeService 来获取和完成这些事件监听器
1
2
GenericEventListenerInstanceQuery createGenericEventListenerInstanceQuery();
void completeGenericEventListenerInstance(String genericEventListenerInstanceId);
Similar to user event listeners, this API is a wrapper on top of the PlanItemInstance queries and operations. This means that the data can also be retrieved through the regular PlanItemInstanceQuery
和 user event listeners 类似, 这个 API 是 PlanItemInstance 查询和操作顶部的包装. 这意味着数据也可以从 PlanItemInstanceQuery 获取.
Note that generic event listeners are not part of the CMMN specification, but are a Flowable-specific addition.
注意 一般事件监听器不是 CMMN 规范的内容, 而是 Flowable-规范 的补充
Automatic removal of event listeners
Automatic removal of event listeners 自动移除事件监听器
The engine will automatically detect when event listeners (user or timer) are not useful anymore. Take for example the following case definition:
引擎会自动监测不再使用的事件监听器(用户或者定时器), 例如下面的case定义:
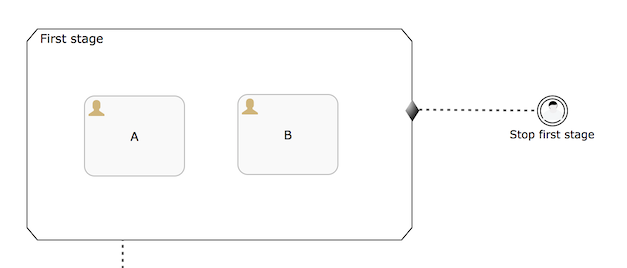
Here, the First stage contains two human tasks (A and B) and it can be exited by a user when the Stop first stage user event is triggered. However, when both tasks A and B are completed, the stage will also complete. If now the user event listener would be triggered, there is nothing that listens to this event anymore. The engine will detect this and terminate the user event automatically.
这里, 第一个阶段,包含两个人工任务(A 和 B), 并且当停止第一个阶段事件被触发, 该阶段会被终止. 然而, 当 A 和 B 都完成后, 该阶段stage 也会完成. 如果这个时候触发用户事件监听器, 将会不起任何作用. 此时引擎将会检测到,并自动决定该用户事件.
The same mechanism also works for event listeners that are referenced by entry sentries:
相同的原理, 适用于两个入口哨兵的监听器场景:
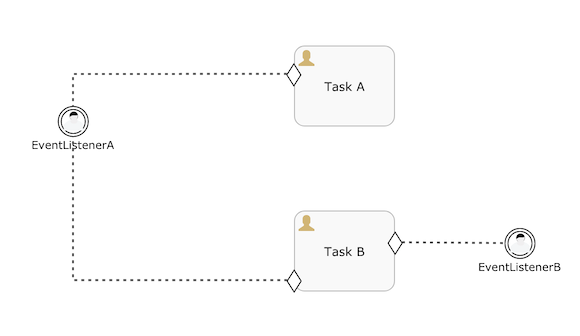
In this case, in the case that EventListenerA would be triggered, EventListenerB is terminated (as nothing is listening to its occurrence anymore).
在这种场景, 如果 EventListenerA 被触发, EventListenerB 会终止(因为没有任何在监听B的发生)
Or, when timer and user event listeners are mixed, the one that is triggered first will also cause the removal of others (when they are not referenced somewhere else):
或者, 当定时器和用户事件监听器被混合使用, 首先被触发的一个会造成其他的移除(当他们没有被别的地方引用)
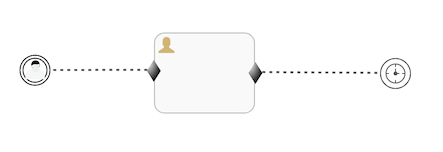
Here, the timer will be removed in case the user event is triggered first (and vice versa).
这里, 定时器会被移除, 如果用户件事监听首先被触发.(反之亦然)
The detection also takes in account plan items that have not yet been created. Take for example the following case definition:
检测还考虑到尚未创建的计划项.如下图所示:
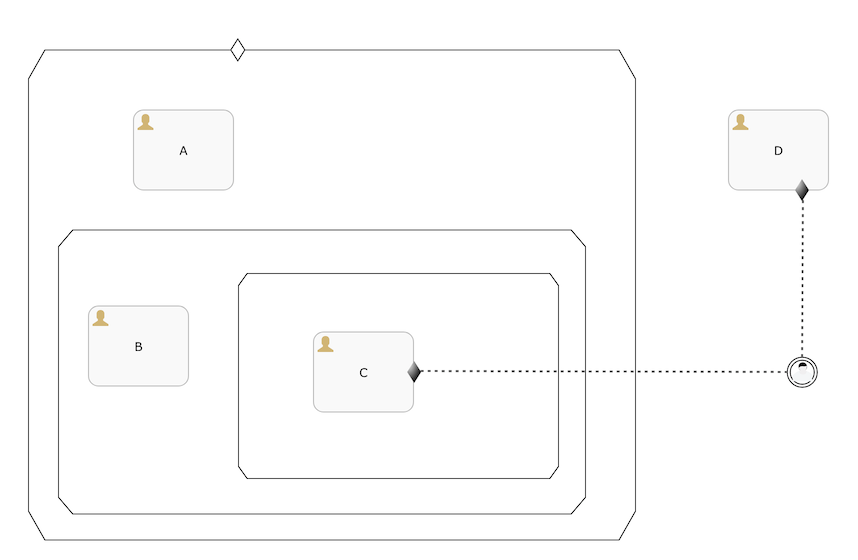
Here, human task C is not yet created when a case instance is started for this case definition. The user event listener will not be removed as long that C has a parent stage that is in a non-terminal state, as this means that the event could still be listened to in the future.
这里, 当case 实例启动后, 人工任务C还未被创建. 只要C具有处于非终止 non-terminal 状态的父级,就不会删除用户事件监听器.这意味着该事件可以在未来依然被监听
Available condition
Available condition 可用条件
All types of event listeners can be configured to have a available condition: an expressions that will guard the available state of the event listener. To explain the use case, take the following case definition:
所有类型的事件监听器都拥有一个 available condition: 一个表达式用来维护事件监听器的可用状态.
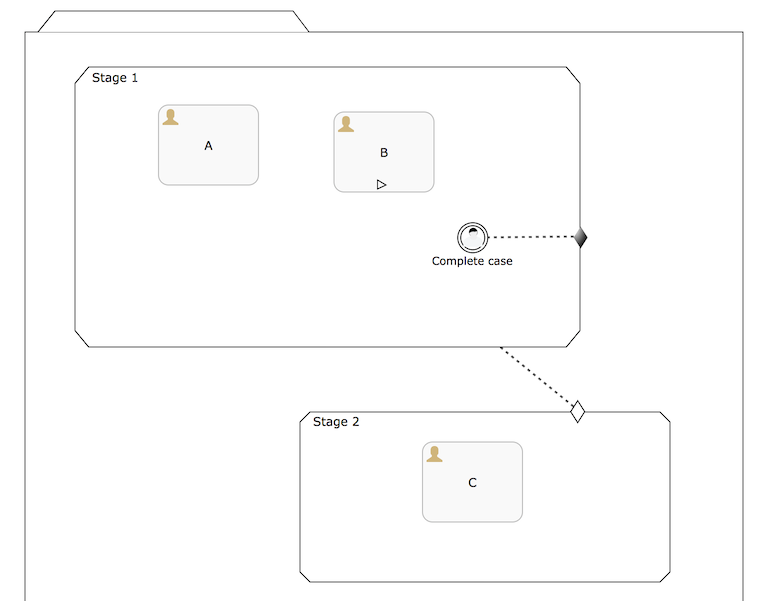
When the case instance is started, Stage 1 (as it has no entry criteria) will be moving immediately from available to active. Similar story for human task A. Human task B will move from available to enabled as it’s manually activated.
当 case实例启动后, stage 1 (没有入口凭证)将立即从可用状态变成活跃状态. 人工任务A类似. 手动激活人工任务B, 它的状态从 available to enabled.
Normally, also the event listener would become available. The life cycle of event listeners is simpler than that of plan items such as human tasks: an event listener stays in the available state until the event happens. There’s no active state like for other plan items. This means that a user could trigger it after start and the stage would be exited.
正常来讲, 事件监听器状态也会变成 available. 事件监听器的生命周期比其他计划项(比如人工任务)简单: 事件监听器保持可用状态, 直到事件发生. 这里没有类似其他计划项一样拥有活跃状态, 这意味着 一个用户可以在开始之后触发它, 然后stage将会退出.
In some use case however, the event listener shouldn’t be available for the user to interact with (or a timer shouldn’t start, when using a timer event listener) unless a certain condition is true.
在一些场景中,除非一个明确满足true的条件, 否则事件监听器不应该可供用户交互(或者当使用定时器监听时, 一个定时器不应该开始) .
In the example above, we want to only create it when the stage doesn’t have any active children (or required) anymore. Setting the availableCondition to ${cmmn:isStageCompletable()} will allow the event listener to be created which makes it move immediately to available. Concretely in this model, when human task A is completed Stage 1 becomes completable (as human task B is manually activated and non-required). This makes the availableCondition of the event listener true and the event listener is now available for a user to decide to exit the stage.
在上述例子中, 我们想要只在该阶段没有任何活跃元素时创建它. 设置 availableCondition to ${cmmn:isStageCompletable()} 将允许事件监听器被创建, 使得它状态立即变成可用. 在这个模型中具体讲, 当人工任务 A 完成, stage 1 变成可完成(因为人工任务B是手动激活的,并且不是必需的)。这使得事件监听器的可用条件变为true, 同时用户也可以决定是否退出该阶段.
Note: this is a Flowable specific addition to the CMMN specification. Without this addition, the event listener would have to be nested within a substage which is protected with entry criteria that listens to the completion of task A.
注意: 这是一个 Flowable 规范对CMMN规范的特定添加.如果没有此添加,则事件监听器将必须嵌套在子阶段中,该子阶段受入口凭证监听任务 A 完成的保护。
Note: if this were an autocompletable stage, the engine would complete the stage automatically when A completes.
注意: 如果是一个可以自动完成的阶段stage, 引擎在A完成时, 自动完成该阶段stage.
6.4.13. Item control: Repetition Rule
6.4.14. Item control: Repetition Rule 条目控制: 重复规则
Plan items on the case model can have a repetition rule: an expression that can be used to indicate a certain plan item needs to be repeated. When no expression is set, but the repetition is enabled (for example, the checkbox is checked in the Flowable Modeler) or the expression is empty, a true value is assumed by default.
案例模型中的计划项可以具有重复规则 repetition rule :一个表达式,可用于指示某个计划项目需要重复。 如果未设置表达式,但启用了重复(例如,在 Flowable Modeler 模型设计器中勾选了复选框)或表达式为空,则默认为 true。
An optional repetition counter variable can be set, which holds the index (one-based) of the instance. If not set, the default variable name is repeitionCounter.
可以设置一个可选的 repetition counter variable_属性,它将保存一个实例对应的索引(从1开始). 如果未设置,默认的变量名为 _repeitionCounter.
If the plan item does not have any entry criteria, the repetition rule expression is evaluated when the plan item is completed or terminated. If the expression resolved to true, a new instance is created. For example, a human task with a repetition rule expression ${repetitionCounter < 3}, will create three sequential human tasks.
如果一个计划项没有设置入口凭证, 当它完成或则停止时,重复准则表达式都会计算. 如果解析为true, 则创建一个新的实例. 例如, 一个人工人有表达式 ${repetitionCounter < 3}, 将会创建3个有序的人工任务.
If the plan item has entry criteria, the behavior is different. The repetition rule is not evaluated on completion or termination, but when a sentry of the plan item is satisfied. If both the sentry is satisfied and the repetition rule evaluates to true, a new instance is created.
如果计划项有设置入口凭证, 表现是不同的. 当完成或中止时, 重复规则不会计算. 只有满足哨兵的条件才会计算.如果同时满足哨兵条件并且重复准则计算为true, 一个新的实例才会被创建.
Take, for example, the following timer event listener followed by a human task. The sentry has one entry criterion for the occur event of the timer event listener. Note that enabling and setting the repetition rule on the task has a visual indicator at the bottom of the rectangle.
例如,下面的计时器事件监听器后面跟着一个人工任务。哨兵对于计时器事件监听器的发生事件有一个入口凭证。注意,在任务上启用和设置重复规则都会在矩形底部有一个可视指示器。
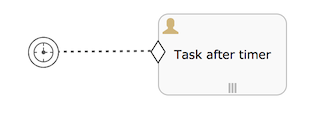
If the timer event listener is repeating (for example, R/PT1H), the occur event will be fired every hour. When the repetition rule expression of the human task evaluates to true, a new human task instance will be created each hour.
如果定时器事件监听器是可重复的(例如, R/PT1H), 每间隔1小时,发生事件 occur event 会被触发. 当人工任务的重复准则计算为true, 每隔1小时,一个新的人工任务实例会被创建.
Note that Flowable allows to have repeating user and generic event listeners. This is contrary to the CMMN specification (which disallows it), but we believe it is needed for having a more flexible way of using event listeners (for example to model a case where a user might multiple times trigger an action that leads to the creation of tasks).
注意, Flowable 允许拥有可重复的用户和一般事件监听器. 这和 CMMN 准则是相反的. 但是我们相信拥有一个更加灵活的方式使用时间监听器是需要的(例如在一个用户需要多次触发一个动作来创建人物的案例模型)
6.4.15. Item control: Manual Activation Rule
6.4.16. Item control: Manual Activation Rule 条目控制: 手动激活准则
Plan items on the case model can have a manual activation rule: an expression that can be used to indicate a certain plan item needs to be manually activated by an end-user. When no expression is set, but the manual activation is enabled (for example, the checkbox is checked in the Flowable Modeler) or the expression is empty, a true value is assumed by default.
案例模型中的计划项可以拥有一个手动激活准则: 一个表达式被提供给终端用户手动激活一个确定的计划项. 当未设置任何表达式, 但是启用了手动激活(例如, Flowable Modeler 中的复选框被选中) 或者表达式为空, 默认值为true.
Stages and all task types can be marked for manual activation. Visually, the task or stage will get a play icon (small triangle pointing to the right) to indicate an end-user will have to manually activate it:
阶段stage 和所有类型任务都可以设置手动激活. 可视化地, 任务或者阶段stage 将会有一个 播放图标 play icon(一个指向右侧的小三角形),指明用户需要手动去激活它.
Normally, when a sentry for a plan item is satisfied (or the plan item doesn’t have any sentries) the plan item instance is automatically moved to the ACTIVE state. When a manual activation is set though, and it evaluates to true, the plan item instance now becomes ENABLED instead of ACTIVE. As the name implies, the idea behind this is that end-users manually have to activate the plan item instance. A typical use case is showing a list of buttons of potential plan item instances that can currently be started by the end user.
正常来讲, 当一个计划项的哨兵条件得到满足(或者没有任何哨兵), 计划项将自动转为活跃状态 ACTIVE. 当设置了手动激活,并且计算结果为true,计划项从活跃状态 ACTIVE 变为已启用状态 ENABLED. 正如名称所示, 背后的想法就是指终端用户需要手动激活计划项. 一个典型的用例就是一个潜在计划项实例的按钮列表.而这些按钮目前可以由最终用户启动.
为了启动一个可启动的计划项实例, 可以使用 CmmnRuntimeService 的 startPlanItemInstance 方法:
1
2
3
4
5
6
7
8
List<PlanItemInstance> enabledPlanItemInstances = cmmnRuntimeService.createPlanItemInstanceQuery()
.caseInstanceId(caseInstance.getId())
.planItemInstanceStateEnabled()
.list();
// ...
cmmnRuntimeService.startPlanItemInstance(planItemInstance.getId());
注意,任务的行为只在计划项实例进入活动状态时被执行。例如,对于人工任务,只有在调用 startPlanItemInstance 方法之后才会创建用户任务。
已启动的计划项实例可以转变为 禁用状态 DISABLED:
1cmmnRuntimeService.disablePlanItemInstance(planItemInstance.getId());
Disabled plan item instances can be enabled again:
禁用的计划项也可以重新被启动:
1cmmnRuntimeService.enablePlanItemInstance(planItemInstance.getId());
注意, 在决定阶段或案例实例终止时,禁用状态 DISABLED 被视为“终端”状态. 这意味着当只有禁用的计划项实例存在,案例实例将终止.
6.4.17. Item control: Required Rule
案例模型中的计划项可以拥有一个要求准则 required rule: 一个表达式被用作被外部stage 或者案例模型要求执行的一个计划项.这可以用来表明案例模型中的计划项哪些是必须的,哪些是可选的.
当未设置任何表达式, 但是启用了 required rule (例如, Flowable Modeler 中的复选框被选中)或者表达式为空, 默认值为true.
required rule 与 父类 stage的 autoComplete 属性一起使用: * 如果 autoComplete 为 false, 这个也是默认值, all 所有子计划项实例必须处于最终状态(完成、终止,等等), 以便由引擎完成阶段计划项实例.
-
如果 autoComplete 为 true, 需要所有要求准则计算为true的子计划项实例进入最终状态. 如果这没有其他处于活跃状态的子元素, 父类阶段 stage 将自动完成.
阶段stage 拥有一个 completeable 属性来用作表示当前条件是否得到满足来完成该stage. 例如, 下面的简单阶段stage, 假设一个哨兵的条件为true, 另一个为false, 则意味着 左边的计划项实例将进入活跃状态, 右侧的将进入可用状态.

调用 cmmnRuntimeService.completeStagePlanItemInstance(String stagePlanItemInstanceId) 完成当前stage是不可能的(抛出异常), 因为有一个活跃状态的子元素存在. 当左侧的用户任务完成, 因为当前没有子元素活跃, completeStagePlanItemInstance 会被调用. 但是对于它自身, 阶段stage 不会自动完成, 因为右边的用户任务还处于可用状态.
如果上面的阶段stage 设置为 autoCompleteable (在底部有一个黑色的小矩形), 右边的计划项设置为必须的(有一个可见的感叹号标记), 表现会不同:
-
如果左边计划项实例是活跃(哨兵为true), 右边不是(哨兵为false). 这种情况下, 当左边任务完成后, stage 实例将会自动完成并且所有必须的计划项实例进入最终状态.
-
如果左右俩个任务都是活跃状态(哨兵都为true)
-
当左边任务完成后, 因为右边实例还处于活跃zhuangt, 当前阶段stage 不会自动完成.
-
当右边任务完成后, 因为左边必须的任务不是出于最终状态(活跃), 当前阶段 stage不会自动完成.
-
-
如果左边任务不是活跃状态, 右边出于活跃. 这种情况下, 当右边任务完成后, 当前阶段stage 不会自动完成, 因为左边必须的任务不是出于一个最终状态. 只有左边任务出于活跃并且完成后, 才能完成当前阶段 stage.
注意, 手动激活规则独立于要求准则. 例如, 以下阶段stage:
这里, 用户任务D是必须的, 任务B是需要手动激活.
-
如果D完成, 当前stage将自动完成. 因为B不是必须的并且不是活跃状态.
-
如果B也是必须的, 即使D已经完成, 还是需要手动激活B(调用 cmmnRuntimeService.startPlanItemInstance(String planItemInstanceId)), 然后当前阶段stage 才能自动完成.
6.4.18. Item control: Completion Neutral Rule
案例模型中的计划项可以拥有一个中立完成准则 completion neutral rule: 一个表达式被用作对于完成父类stage 或者案例模型, 一个计划项是中立的(非必须). 这可以用来表明案例模型中的计划项哪些是必须的,哪些是可选的. 相比在某些时候使用 required rule 和 autoComplete, 会更加灵活.
注意, 中立完成准则 Completion Neutral Rule 不是 CMMN 1.1规范, 是 Flowable 规范的补充.
依照规范, 出于 AVAILABLE 可用状态的阶段 stage 不能被完成, 除非 autoComplete 属性为true, 并且计划项不是必须的. 例如, 一个计划项保持可用 AVAILABLE 状态, 哨兵条件未满足. 这意味 除非计划项被标记为非必须,并且 父类 stage 设置 autoComplete, 否则 父类stage 不会完成. 缺点是, 一旦一个阶段被标记为自动完成,所有子计划项目都需要为所需的规则进行配置, 这在某些用例中是冗长和繁重的工作
中立完成准则 Completion Neutral Rule, 与 autoComplete-required 机制相反,完成中立规则从“自底向上”工作:一个计划项目可以单独标记为中立,而无需标记任何其他计划项目.
当计划项都计算为true, Required Rule 优先.
To summarize: 总结:
-
一个计划项设置为 "completion neutral", 如果他出于活跃 AVAILABLE 状态(等待一个入口哨兵凭证), 将允许 父类stage 自动完成. 这意味着一个计划项目相对于它的父阶段完成评估是中立的.
-
在以下条件中, 一个 stage 会保持活跃 ACTIVE 状态:
-
它拥有至少一个出于活跃状态的计划项
-
它拥有至少一个带有 requiredRule , 处于可用 AVAILABLE 或者 启用 ENABLE 状态的计划项.
-
它没有被标记为 autoComplete, 拥有至少一个 计划项处于 启用 ENABLED 状态 (不管 必须准则 requiredRule)
-
它没有被标记为 autoComplete, 拥有至少一个 计划项处于 可用 AVAILABLE 状态并且 不是 完成中立 completionNeutral
-
-
一个阶段 将会完成:
-
它不包含子元素, 或者所有子计划项 都是处于 一个 终止 Terminal 或者 半终止 Semi-terminal 状态 (关闭, 完成, 禁用, 失败)
-
它没有标记为 autoComplete 且所有存在的子计划项处于 可用 AVAILABLE 状态, 并且是 完成中立 completionNeutral ,而不是必须的
-
它标记为 autoComplete 且所有子计划项非必须 not required, 处于 已启用 ENABLED 或者 可用 AVAILABLE 状态. (不管 完成中立 completionNeutral, 要求准则优先)
-
6.5. Sentry evaluation
6.6. 哨兵计算
在任何案例定义中, 哨兵扮演一个重要的角色. 它们提供了一个强大的声明式配置方式来激活正确的计划项或者自动停止.因此,Flowable CMMN 引擎核心逻辑最重要的部分之一是计算哨兵,以查看在一个案例实例中发生了什么状态更改。
6.6.1. 什么时候计算哨兵?
在任何状态发生改变或者新事件发生,具体地说,这意味着:
-
当一个案例实例启动.
-
当一个等待状态的计划项被触发继续.(比如人工任务)
-
当案例实例相关变量发生改变(新增, 修改, 或删除)
*当计划项实例状态改变(比如 通过 RuntimeService 停止, 一个手动计划项启动,等等)
-
当RuntimeService#evaluateCriteria 方法手动触发.
伴随着状态改变的进行, 引擎会有计划地一直对当前活跃的哨兵进行计算.例如,假设一个人工任务的完成满足另一个人工任务的出口哨兵。第二个人工任务的状态更改将再次使用此新信息对所有活动哨兵进行新的评估。当最后一次评估没有发生变化时,引擎认为状态稳定,停止计算.
6.6.2. Concepts 概念
哨兵包含两部分:
-
与其他计划项生命周期相关的一个或者多个 onParts
-
零个或者一个 if条件
注意以下案例定义:
假设(上图中未展示出来)
-
任务C的入口哨兵监听任务 A和B的完成 complete 事件
-
出口哨兵监听 用户事件监听器的发生 occur 事件 'Stop C'
-
入口哨兵有个表达式设置为 ${var:eq(myVar, hello world)}
在这个简单例子中, 入口哨兵 有两个 onParts 和 一个 ifPart. 退出哨兵只有一个 onPart.
当案例实例启动后, 人工任务A和B被创建(他们没有入口哨兵), 很快进入活跃 active 状态. C因为入口哨兵条件不满足, 处于可用 available 状态. 用户事件监听器“Stop C”从一开始就可用,因此可以被触发.
当任务A和B都完成并且变量 myVar 设置为 'hello world', 入口哨兵条件满足并且触发. C后面的计划项实例被移动到active状态, 同时,人工任务C被创建(例如,现在可以通过 TaskService 查询它). 当’Stop C’被触发(通过 CmmnRuntimeService#completeUserEventListenerInstance 方法),出口哨兵条件满足, C被中止.
如果 'Stop C' 在 C变成活跃 active 状态前被触发, 它的计划项实例将被中止, 出口哨兵也将不再监听任何.
6.6.3. 默认行为
当一个案例实例启动后
CaseInstance caseInstance = cmmnRuntimeService.createCaseInstanceBuilder()
.caseDefinitionKey("myCase")
.start();
入口哨兵条件会立即被计算, 因此当案例实例启动会有一个有序的循环计算.
注意, 如果使用像_${myVar == hello world}_ 条件表达式不会起作用. 引擎会抛出 PropertyNotFound 异常, 因为它不知道 变量myVar.
为了解决上述问题:
-
在启动时传一个 myVar 变量
-
做一个非空校验, 类似 ${planItemInstance.getVariable(myVar) != null && planItemInstance.getVariable(myVar) == hello world}
-
或者更简单地, 使用 表达式函数 expression functions , 类似 ${var:eq(myVar, hello world)} 考虑到变量可能不存在的情况
默认的计算逻辑有“缓存”,这意味着当哨兵的一部分条件得到满足时,引擎将存储并在随后的计算中并"记住"这个值.
这意味着, 从某一部分(onPart或ifPart of the sentry)得到满足的那一刻起, 该特定部分在下一次评估中不再被评估, 而是被认为是正确的.
在上述例子中,这是任务A相对于B通常会在另一个时间点完成。例如,如果任务A完成后,任务C哨兵的一部分说“我监听任务A完成“得到满意,这事实上为将来被缓存。如果现在B完成了, 它也被存储。如果 myVar 变量得到正确的值,ifPart也会触发,整个岗兵和任务C也会被激活。当然,也可以先满足变量值,然后再满足任务. 关键是这并不重要,因为引擎会保存之前满足的部分条件
这是流程引擎的默认行为, 可以设置 哨兵 triggerMode 为 default 覆盖. 在Flowable Modeler 中增加一个新计划项时自动被设置. 当不设置(例如从另一个工具导入模型)时, triggerMode 默认是 default.
6.6.4. Trigger mode "onEvent" 事件触发模式
默认行为(查看前面部分)是保存先前被满足的部分. 这是最常用和最安全的方法(也是对哨兵进行推理时通常期望的方法).
另一种哨兵触发模式称为“onEvent”。在这种模式下,引擎将有关于哨兵的部分保存,不会保存*not remember*过去满足的任何部分。这在高级用例中有时是需要的。以下面的例子为例:
这里, 案例模型是一个有三个子阶段stage. 所有子阶段都可以重复. 子阶段B和C有一个入口哨兵用来等待阶段A的完成. 同理(未展示出来), 两个哨兵都有一个变量的依赖条件.
在高级用例中, 可能想要或需要哨兵部分(特别是包含条件的ifPart)仅在相关计划项的生命周期事件发生时才进行计算。在本例中,正是Stage A的完成事件。 对于这些用例,可以将哨兵的 triggerMode 设置为onEvent。顾名思义,这意味着哨兵的计算只在引用事件发生时发生,而不考虑对过去事件的缓存。
具体地说, 在这里的例子中,只有在阶段A完成时(而不是在其他时刻)才会计算入口哨兵的情况. 这与一般的评价规则有很大的不同. 在这个特殊的例子中,它确实使管理变量变得更容易, 因为条件只在一个精确的时刻进行评估,并且不需要担心由于某个变量在某个时间点的具体值而触发某个哨兵的部分. 特别是在本例中,所有子阶段都在重复,这需要做很多工作。这是一种功能强大的机制,但对于高级建模人员来说,这意味着他们对案例模型和这种 triggerMode 的语义具有内在的知识.
注意,在计算哨兵时,引擎认为所有的事件都是同时发生的。以下面的案例定义为例:
假设所有的哨兵使用 triggerMode onEvent 的设置. 如果任务A完成, 这会使任务B退出, 任务C也会退出. 所以,即使有两种截然不同的生命周期事件(A被完成和B被退出),人们可能会认为 onEvent 的字面意思是, 有两种截然不同的计算发生, 而另一部分C的退出哨兵的缓存被忘记.引擎足够聪明地看到,他们是相同的计算周期且任务C也将退出.
从技术上讲: onEvent 哨兵存在缓存,更具体地说,是用于在同一API调用(或事务,简单地说)期间发生的计算.
Important onEvent是一种功能强大的机制,只有当很好地理解语义时才应该使用它。如果不仔细检查用例,可能会创建由于没有正确的配置哨兵而卡住的用例模型。
(例如, 假设一个哨兵有一个onPart监听一个计划项的完成情况,还有一个带有条件的ifPart。如果计划项完成, 从而触发onPart, 但是由于某种原因缺少了条件中使用的变量…… ifPart将永远不会触发,case实例可能会陷在一个不想要的状态).
7. 体系结构
本章从高层次的角度简要介绍了CMMN引擎的内部结构。当然,由于CMMN引擎代码是开源的,因此可以通过深入了解源代码来找到实际的实现细节。
如下图所示,CMMN引擎是Flowable引擎生态系统的一部分,其设计方式与其他引擎类似。CMMN引擎基于CMMN特定服务和共享服务构建:任务,变量,身份和作业服务,它们独立于引擎。 在较低级别,实体和数据管理器层负责低级别持久性,相当于其他引擎。
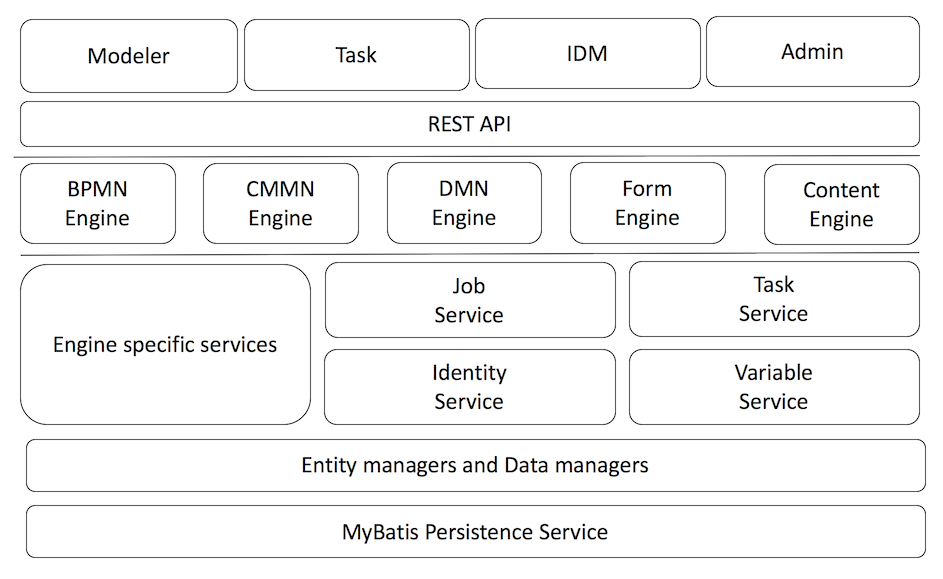
通过使用共享服务,这也意味着例如来自BPMN和CMMN引擎的任务将最终结合在一起,并且可以通过相同的API查询和管理。类似地,对于异步执行器:定时器和异步作业使用相同的逻辑,甚至可以由中央执行器管理。
共享服务架构有第二个好处。通常情况下,当引擎一起使用时,引擎将尽可能共享资源,数据库事务将跨越多个引擎操作的调用,查找缓存是常见的,并且持久性是独立于引擎本身处理的。
CMMN引擎的设计原理与Flowable项目的其他引擎相同。下图给出了使用CMMN引擎时涉及的不同组件的高级概述:
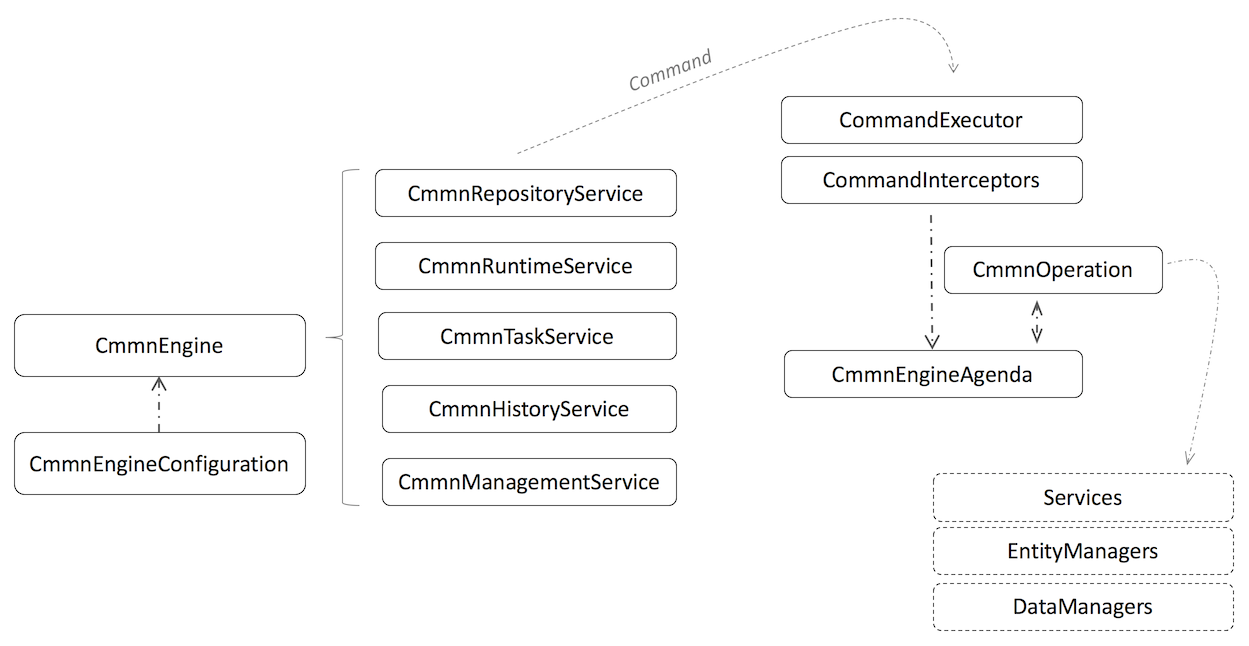
从高层次来看:
一个CmmnEngine实例是从CmmnEngineConfiguration创建的。可以从配置文件或以编程方式创建配置实例。
CmmnEngine以服务的形式提供对Flowable CMMN API的访问:CmmnRepositoryService、CmmnRuntimeService、CmmnTaskService、CmmnHistoryService、CmmnManagementService。服务的命名及其职责与其他引擎类似。
每个API方法都转换为Command实例,此Command实例传递给CommandExecutor,其中包括使一些CommandInterceptors。这些拦截器具有各种职责,包括处理事务。
最终,Command通常(除非是纯数据修改Command)在CmmnEngineAgenda上计划CmmnOperation。
操作将从CmmnEngineAgenda中获取,直到不再进行操作为止。通常,操作将计划新操作作为其逻辑的一部分。
操作中的逻辑将调用较低级别的服务和/或实体管理器。
BPMN和CMMN引擎之间的一个很大区别是BPMN引擎通常是“本地的”:引擎查看当前状态,检查进程中的前面的信息并继续(当然这是一个简化,这有很多不适用的操作,但从概念上做出区分,这是正确的)。CMMN引擎的工作方式不同:在CMMN中,数据起着重要作用,数据的更改可以在案例定义中的各个位置触发很多事情。因此,只要发生更改,就会经常计划和执行EvaluateCriteriaOperation。当检测到重复或无用的评估时,引擎会对这些评估进行优化。
CMMN引擎工作的核心是计划项目实例的概念,表示当前在案例中存在哪些计划实例项以及它们具有哪种状态。与BPMN完全不同,CMMN为计划项定义了严格的状态生命周期。这在CmmnRuntimeService方法,查询API和PlanItemInstance对象的数据字段部分中表示。
可以通过将日志记录设置为议程包的调试来检查议程的工作,操作以及如何处理计划项实例。例如,使用log4j时:
log4j.logger.org.flowable.cmmn.engine.impl.agenda=DEBUG这样记录的信息如下:
Planned [Init Plan Model] initializing plan model for case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122
Planned [Change PlanItem state] Task A (id: planItemTaskA), new state: [available] with transition [create]
Planned [Change PlanItem state] PlanItem Milestone One (id: planItemMileStoneOne), new state: [available] with transition [create]
Planned [Change PlanItem state] Task B (id: planItemTaskB), new state: [available] with transition [create]
Planned [Change PlanItem state] PlanItem Milestone Two (id: planItemMileStoneTwo), new state: [available] with transition [create]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'create' having fired for plan item planItemTaskA (Task A)
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'create' having fired for plan item planItemMileStoneOne (PlanItem Milestone One)
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'create' having fired for plan item planItemTaskB (Task B)
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'create' having fired for plan item planItemMileStoneTwo (PlanItem Milestone Two)
Planned [Activate PlanItem] Task A (planItemTaskA)
Planned [Change PlanItem state] Task A (id: planItemTaskA), new state: [active] with transition [start]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'start' having fired for plan item planItemTaskA (Task A)
Planned [Change PlanItem state] Task A (id: planItemTaskA), new state: [completed] with transition [complete]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'complete' having fired for plan item planItemTaskA (Task A)
Planned [Activate PlanItem] PlanItem Milestone One (planItemMileStoneOne)
Planned [Change PlanItem state] PlanItem Milestone One (id: planItemMileStoneOne), new state: [active] with transition [start]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'start' having fired for plan item planItemMileStoneOne (PlanItem Milestone One)
Planned [Change PlanItem state] PlanItem Milestone One (id: planItemMileStoneOne), new state: [completed] with transition [occur]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'occur' having fired for plan item planItemMileStoneOne (PlanItem Milestone One)
Planned [Activate PlanItem] Task B (planItemTaskB)
Planned [Change PlanItem state] Task B (id: planItemTaskB), new state: [active] with transition [start]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'start' having fired for plan item planItemTaskB (Task B)
Planned [Change PlanItem state] Task B (id: planItemTaskB), new state: [completed] with transition [complete]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'complete' having fired for plan item planItemTaskB (Task B)
Planned [Activate PlanItem] PlanItem Milestone Two (planItemMileStoneTwo)
Planned [Change PlanItem state] PlanItem Milestone Two (id: planItemMileStoneTwo), new state: [active] with transition [start]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'start' having fired for plan item planItemMileStoneTwo (PlanItem Milestone Two)
Planned [Change PlanItem state] PlanItem Milestone Two (id: planItemMileStoneTwo), new state: [completed] with transition [occur]
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122 with transition 'occur' having fired for plan item planItemMileStoneTwo (PlanItem Milestone Two)
Planned [Evaluate Criteria] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122
No active plan items found for plan model, completing case instance
Planned [Complete case instance] case instance bfaf0e64-eaf4-11e7-b9d0-acde48001122